트랜스포머를 활용한 자연어 처리의 다양한 분야에서의 예제를 알기 쉽게 학습
1. 텍스트 전처리
텍스트 전처리는 텍스트 데이터를 분석하기 전에 정제하는 과정입니다. 이를 통해 데이터의 일관성을 유지하고 분석에 필요한 정보를 추출할 수 있습니다.
텍스트 전처리의 대표적인 예시로는 다음과 같은 것들이 있습니다.
- 문장 부호 제거: 문장 부호를 제거하여 텍스트를 정제합니다. 예를 들어, "Hello, World!"에서 "Hello World"로 변경할 수 있습니다.
- 대소문자 통일: 대소문자를 통일하여 일관성을 유지합니다. 예를 들어, "Hello"와 "hello"를 모두 "hello"로 변경할 수 있습니다.
- 불용어 제거: 불용어를 제거하여 분석에 불필요한 단어들을 제외합니다. 예를 들어, "the", "a", "an"과 같은 단어들을 제거할 수 있습니다.
이 외에도 텍스트 데이터에 따라 다양한 전처리 과정이 필요할 수 있습니다. 이러한 과정들은 자연어 처리 분야에서 굉장히 중요한 역할을 합니다.
학습을 위해 텍스트 데이터를 준비하셨다면, 이러한 전처리 과정을 적용하여 데이터를 정제하고 일관성 있는 형태로 만들어보세요. 이후 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있을 것입니다.
텍스트마다 적절한 분석 기법은 따로 있다!
당신의 경쟁력을 완성할 텍스트 분석 전략서
텍스트에서 좋은 정보를 찾는 이가 뛰어난 경쟁력을 갖춘다. 머신러닝 기반 자연어 처리 기술이 발전함에 따라 다양한 텍스트 분석 기법이 속속 등장하고 있다. 수많은 기법 중에서 어떤 방법을 언제 어떻게 사용해야 유용한 정보를 얻어낼 수 있을까? 이 책은 유엔총회 일반토의 연설문부터 트위터, 로이터 뉴스 기사 등 다양한 데이터셋을 사용하여 상황별로 가장 유용한 텍스트 분석 기법을 소개한다. 실제 모범 사례를 기반으로 상황에 맞게 설계한 텍스트 전처리 파이프라인 구축, N-그램 분석, 텍스트 벡터화 등 다양한 전략으로 텍스트 분석과 자연어 처리를 정복해보자.
젠스 알브레히트
뉘른베르크 공과 대학 컴퓨터공학과 전임 교수다. 주된 분야는 데이터 관리 및 분석으로, 특히 텍스트에 중점을 둔다. 컴퓨터과학 박사 학위를 받고 업계에서 컨설턴트 및 데이터 설계자로 10년 이상 일한 뒤, 2012년 학계로 돌아왔다. 빅데이터 관리 및 분석에 관한 여러 편의 글을 기고했다.
싯다르트 라마찬드란
현재 소비재 산업용 데이터 제품을 구축하고 있는 데이터 과학자 팀의 리더다. 통신, 은행, 마케팅 산업 전반에 걸쳐 소프트웨어 엔지니어링 및 데이터 과학 분야에서 10여 년 경력을 쌓았다. 또한 테크크런치에 소개된 왓츠앱용 스마트 개인 비서 앱 기업 WACAO를 공동 설립했다. 인도 공과대학교 루르키 캠퍼스에서 공학 학사 학위를, 인도 경영대학교 코지코드 캠퍼스에서 MBA를 취득했다. 기술을 이용해 현업의 문제를 해결하는 일에 열정적이며 개인 프로젝트로 해킹을 하며 여가를 즐긴다.
크리스티안 윙클러
데이터 과학자이자 머신러닝 아키텍트다. 이론 물리학 박사 학위를 받고 20년 동안 대용량 데이터 및 인공지능 분야에서 일하며 대량 텍스트 처리를 위한 확장 가능한 시스템 및 지능형 알고리즘에 주력했다. 데이터나이징 유한회사를 창립하고 여러 컨퍼런스에서 강연하며 머신러닝/텍스트 분석을 주제로 다수의 글을 게재했다.
심상진
국내 IT 대기업에서 자연어 데이터 분석 및 모델러로 활동 중이다. 물리학을 전공하고, 임베딩 소프트웨어 개발, 단백질 분자 모델링 연구 및 시스템 파이프라인 구축, 기상/지리 데이터 관련 시각화 및 관리 소프트웨어 방면에서 경력을 쌓았다. 데이터 분석을 평생의 업으로 생각하고 일에 매진하고 있다. 자연어 처리가 주 업무이며, 데이터 수집 방법과 레이블링의 효율적 처리 방법을 강구하는 중이다. BERT보다 작으면서도 효율적인 구성을 가진 모델을 연구하며, 자연어를 기계어에 일대일로 대응시킬 방법을 모색하고 있다. 무엇보다 얼마 전에 태어난 아기에게 애정 어린 관심을 쏟으며 연구를 게을리하지 않으려고 노력한다.
이럴 땐 이렇게!
98가지 분석 전략으로 텍스트를 정복하라
텍스트는 문맥에 크게 의존하고 있어 컴퓨터가 이해하는 데 많은 어려움이 있었다. 하지만 최근 들어 통계 기술과 머신러닝 알고리즘이 발전하며 텍스트를 분석하는 다양한 방식이 탄생했다. 그렇다면 이 많은 텍스트 분석 기법 중에서 내가 분석하려는 텍스트에 딱 맞는 방법을 찾을 수 있을까? 이 책은 저자들이 여러 비즈니스 영역에서 텍스트 분석 프로젝트를 진행한 경험을 바탕으로 텍스트에 맞는 분석 전략 98가지를 소개한다.
각 장에서는 API나 크롤링을 이용한 텍스트 수집, 정규표현식이나 인공지능을 활용한 유사 단어 탐색, 단어 사이 관계를 파악하는 지식 그래프 생성 같은 텍스트 분석의 모든 과정마다 필요한 다양한 전략을 소개한다. 이때 사용하는 데이터는 유엔총회 연설 데이터, 깃허브 이슈 모음, 커뮤니티 게시글 모음 등 실제로 마주할 수 있는 텍스트로 여러 상황이나 데이터에 적합한 맞춤형 분석 전략을 소개한다. 전략마다 넘파이(NumPy), 트랜스포머스(Transformers), 사이킷런(scikit-learn), 사이파이(SciPy), 스페이시(spaCy) 등 텍스트 분석에 필요한 라이브러리를 사용하며, 각자 가지고 있는 데이터와 요구 사항에 맞게 변경해 분석해볼 수 있도록 코드의 뼈대도 함께 제공한다. 지금 당장 새로운 정보를 알아내야 할 텍스트가 있다면 이 책에서 소개하는 적절한 전략을 찾아 텍스트를 정복하자.
Lexical Semantics & WSD
어휘 의미론 및 WSD
어휘 의미론은 단어의 의미를 분석하는 것을 의미한다. 그리고 단어의 의미를 이해하는 것을 WSD(Word Sense Disambiguation)라 합니다.
One lemma는 여러 의미를 가질 수 있다. 그리고 그 의미는 우리가 잘 아는 사전에 저장되어 있다. (그래서 사전을 감지하여 목록을 만들었다.)

언어학에서 동음이의어(Homonyms), 동형이의어(Homographs) 등 word sense를 정의하고 있지만, 일단 NLP Homonyms , Homographs 를 정확히 구분하는 것은 관심을 가지고 있습니다 . (철자가 다르면 다른 단어라고 인식하기 때문에 고대의 필요가 없습니다. 마찬가지로 소리를 구분하는 것이 되기 때문에 Heteronyms도 관심이 없습니다.)

게다가 유사성 / 관련성 와 같은 의미론적 관계들이 있다.
WSD (Word-sense disambiguation)는 문장에서 그 단어가 아마도 의미를 찾는 것을 의미한다. 그리고 그 방법에는 지식 기반 와 감독된 ML 접근 방식이 있다.
※ 말의 의미 변별이라는 것도 있다. 사전에 정의된 단어로 의미를 찾는 것이 아니라 비슷한 의미를 가진 단어를 그룹화하는 것이다. 감독되지 않은 ML과 보상된다.
WSD를 전체 개념에 대해 수행하는 것은 다소 어려운 문제다. (전단어 과제) 충분히 예측 데이터를 충분히 완충하기로 했기 때문이다. 이 경우에는 ML로 표지하기 위해 유일한 방법은 모든 단어에 대한 사전을 찾을 수 있습니다.
반면 일부 단어를 선택해서 WSD 문제를 풀 각 단어마다 분류자를 만들 수 있을 것 같은 supervised ML을 적용할 수 있다. ( Lexical sample task ) 우리는 이 경우에 사용할 수 있도록 허용합니다.

Lexical sample task는 모든 단어가 아니라 일부 단어(sample)의 의도를 파악하는 것이다. 이러한 작업을 유용하게 하기 위한 특별한 사전이 있다.

SYNSET은 동의어의 집합을 의미하는 과학, WordNet이라는 사전과 마찬가지로 동의/유사어를 함께 표현한 사전들이 있어 학습 데이터로 유용하게 사용할 수 있다.
윌리엄 이런 단어의 집합이 아니라 문장에서 그 단어가 쓰였는가를 보여주는 훈련 코퍼스가 필요한 데 그 데이터를 만드는 것이 쉽지 않습니다.

가장 잘만 들어왔다고 평가되는 훈련 코퍼스는 SemCor이다.

SemCor는 각각의 단어별로 POS와 WordNet에서 sense_number가 함께 기록된 훌륭한 데이터셋이다.
그럼 이제 주어진 문장을 교정해야 할 때, 모델에게 지급을 주는 개념으로 텍스트의 특징 벡터를 초점을 맞추는 것이 조금 도움이 된다.

위 그림은 특징 벡터 의 예제를 보여줍니다. bank라는 단어에 SHORE라는 꼬리표를 달아주기적인 조건으로 주변에 어떤 단어가 굳거나 나타나야 하는지 사진을 보여줍니다. 즉, 주변에 물고기, 강가 1번씩 나타나면 해안, 수표, 관심이라는 단어가 1번 이상 나타나면 금융의 의미를 얻는다는 특징 추출 규칙을 정의한 예이다.
이제 이 특징 벡터를 가지고 ML을 뽑을 수 있다는 것을 알 수 있습니다. 이 때 사용할 수 있는 방법은 대체로 가능합니다.
- 나이브 베이즈
- 의사 결정 트리
- SVM
- K-NN
- 신경망
- 그래픽 모델
- 로그 선형 모델
※ 관련 연구 진행에 대해 자세히 알아보기로 한다.
그럼 이제 모델이 잘 만들어졌다면 그 모델의 성능을 정량적으로 평가할 수 있어야 합니다.

이 때 평가 척도가 되어 Precision, Recall을 사용하여 Precision, Recall을 함께 고려하는 F1 점수를 주로 사용한다.
2. 토큰화
토큰화(Tokenization)는 텍스트 데이터를 분석하기 위해 작은 단위로 쪼개는 과정입니다. 이 과정을 거치면 문장이나 단어와 같은 작은 단위로 쪼개진 토큰들을 얻을 수 있습니다.
토큰화의 대표적인 예시로는 다음과 같은 것들이 있습니다.
- 공백 기반 토큰화: 공백을 기준으로 문장을 분리합니다. 문장 단위로 텍스트를 쪼갭니다. 예를 들어, "Hello. How are you?"에서 "Hello", "How are you?"로 분리할 수 있습니다.
- 문장 부호 기반 토큰화: 문장 부호를 기준으로 문장을 분리합니다. 단어 단위로 텍스트를 쪼갭니다. 예를 들어, "I love Natural Language Processing"에서 "I", "love", "Natural", "Language", "Processing"으로 분리할 수 있습니다.
- 단어 기반 토큰화: 단어를 기준으로 문장을 분리합니다. n-gram 토큰화로 연속된 n개의 단어를 하나의 토큰으로 취급합니다. 예를 들어, "I love Natural Language Processing"에서 2-gram으로 분리하면 "I love", "love Natural", "Natural Language", "Language Processing"으로 분리할 수 있습니다.
이 외에도 텍스트 데이터에 따라 다양한 토큰화 방법이 존재합니다. 이러한 과정들은 자연어 처리 분야에서 굉장히 중요한 역할을 합니다.
학습을 위해 텍스트 데이터를 준비하셨다면, 이러한 토큰화 과정을 적용하여 데이터를 작은 단위로 쪼개보세요. 이후 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있을 것입니다.
Tokenization: 어절, 형태소, 음절, 자모 단위 토큰화
텍스트를 처리하기 이전에, 처리하고자 하는 토큰의 단위를 정의하는 것은 중요하다.
텍스트를 어떤 토큰의 단위로 분할하냐에 따라 단어 집합의 크기, 단어 집합이 표현하는 토큰의 형태가 다르게 나타나며
이는 모델의 성능을 좌지우지하기도 한다.
이처럼 텍스트를 토큰의 단위로 분할하는 작업을 토큰화(tokenization)라고 한다.
> 어절(단어)
기본적으로 자연어처리에서는 어절(단어) 단위로 구분한다.
예를 들어, "나는 학교에 간다" 라는 문장을 어절 단위로 토큰화하면,
[나는, 학교에, 간다]와 같이 띄어쓰기 기준으로 문장이 분할된다.
이를 어절 단위 토큰화라고 한다.
> 형태소 (KoNLPy, KLT2000)
(형태소: 의미가 있는 가장 작은 말의 단위)
한국어는 교착어의 특성으로, 하나의 단어가 여러개의 형태소로 이루어져있다.
예를 들어, "학교에"는 '학교(명사)'+'에(조사)'와 같이 명사와 조사의 조합으로 이루어진다.
이를 형태소 단위 토큰화라고 하며, 형태소 토큰화를 위한 형태소 분석기가 존재한다.
특히, python에서는 형태소 분석기 툴을 이용하여 쉽게 형태소 토큰화 작업을 할 수 있다.
KoNLPy는 python에서의 형태소 분석기 모듈을 제공하며,
이 안에는 Hannanum, Kkma, Komoran, Mecab, Okt의 형태소 분석기가 있다.
KoNLPy에서는 토큰화된 형태소 토큰과 형태소 태깅을 함께 출력하는 pos 함수와
토큰화된 형태소만을 출력하는 morphs 함수, 명사만 추출하는 nouns 함수 등이 제공된다.
KoNLPy에서 제공하는 형태소 분석기 중 Okt와 Mecab이 가장 빠른 실행시간을 보였다.

각각의 형태소 분석기들은 형태소를 분할하는 기준이 해당 알고리즘에 따라 다르게 나타나기 때문에
토큰화를 통해 구성되는 단어 집합과 단어 집합의 크기 등이 다르게 표현된다.
KoNLPy 이외에 C기반의 형태소 분석기인 KLT2000이 공개되어 있다.
KLT2000은 C 기반의 형태소 분석기이며 KoNLPy보다 빠른 실행시간으로 형태소 토큰화가 가능하다.
KLT2000에는 색인어 추출 기반의 명사를 추출하는 index2018과 모든 어절에 대한 형태소 분석 결과를 추출하는 kma가 존재한다.
해당 형태소 분석기는 EUC-KR 기반의 텍스트를 처리하는 것을 기본으로 하기 때문에
기본 입력 파일이 EUC-KR의 텍스트로 작성되어 있어야하는 점을 주의해야한다.
> 음절
한국어는 하나의 단어가 형태소의 조합으로 구성되어 있지만,
이는 또다른 표현으로는 음절의 조합으로 구성되어 있다.
즉, 어절 혹은 형태소는 결국 음절 간의 조합으로 표현되어 있다.
예를 들어, "학교에"라는 어절은 [학, 교, 에]와 같이 음절 간의 조합으로 표현이 가능하다.
뿐만 아니라, "나는 학교에 간다"는 [나, 는, 학, 교, 에, 간, 다]와 같이 하나의 음절 단위로 표현이 가능하다.
이처럼 텍스트를 어절과 형태소가 아닌 음절로 표현이 가능하다.
텍스트를 음절로 표현할 때,
단어 사이에 존재하는 띄어쓰기(공백)을 음절에 포함할 것인지, 아닌지를 고려해야하며,
띄어쓰기(공백)을 음절에 포함할 경우, 단어 집합에도 띄어쓰기(공백)에 대한 토큰이 존재하게 된다.
> 자모
한국어는 자음과 모음의 체계로 구성되어 있으며, (초성, 중성, 종성)으로 하나의 음절을 표현한다.
자모는 텍스트로 표현할 수 있는 작은 단위이며, 한국어의 특성이 나타난다.
영어의 경우, 자음과 모음이 하나의 음절을 구성하는 것이 아닌 각각이 하나의 음절(char)를 표현하기 때문에
'자모' 단위 토큰에 대한 개념이 한국어와 다르게 나타난다.
이러한 점에서 자모 단위 토큰화는 한국어의 특성에서 나타난다.
예를 들어, "학교에"라는 어절은 [ㅎ,ㅏ,ㄱ,ㄱ,ㅛ,ㅇ,ㅔ]와 같이 자음과 모음으로 표현이 가능하다.
#. 한국어의 초성, 중성, 종성은 다음과 같이 존재한다.
- 초성(19)
: ㄱ, ㄲ, ㄴ, ㄷ, ㄸ, ㄹ, ㅁ, ㅂ, ㅃ, ㅅ, ㅆ, ㅇ, ㅈ, ㅉ, ㅊ, ㅋ, ㅌ, ㅍ, ㅎ
- 중성(21)
: ㅏ, ㅐ, ㅑ, ㅒ, ㅓ, ㅔ, ㅕ, ㅖ, ㅗ, ㅘ, ㅙ, ㅚ, ㅛ, ㅜ, ㅝ, ㅞ, ㅟ, ㅠ, ㅡ, ㅢ, ㅣ
- 종성(28)
: (없음), ㄱ, ㄲ, ㄳ, ㄴ, ㄵ, ㄶ, ㄷ, ㄹ, ㄺ, ㄻ, ㄼ, ㄽ, ㄾ, ㄿ, ㅀ, ㅁ, ㅂ, ㅄ, ㅅ, ㅆ, ㅇ, ㅈ, ㅊ, ㅋ, ㅌ, ㅍ, ㅎ
위에서 설명한 각 토큰의 단위(어절, 형태소, 음절, 자모)에 따라 텍스트의 분할이 가능하며,
텍스트를 처리하기 이전에 어떠한 토큰 단위로 텍스트를 처리하느냐가 중요한 요인으로 작용할 수 있다.
3. 단어 임베딩
원-핫 인코딩: 각 단어를 고유한 벡터로 표현합니다. 단어 임베딩(Word Embedding)은 단어를 벡터로 표현하는 기법으로, 자연어 처리 분야에서 굉장히 중요한 역할을 합니다.
원-핫 인코딩은 범주형 변수를 수치형 변수로 변환하는 방법 중 하나로, 각 범주별로 이진(0 또는 1) 값으로 나타내어 변수를 표현합니다.
예를 들어, "사과", "바나나", "딸기"와 같은 과일을 범주형 변수로 가지는 경우, 이를 원-핫 인코딩하여 각 과일을 0 또는 1의 값으로 나타낼 수 있습니다.
| 과일 | 사과 | 바나나 | 딸기 | |------|------|--------|------| | 사과 | 1 | 0 | 0 | | 바나나 | 0 | 1 | 0 | | 딸기 | 0 | 0 | 1 |
이렇게 원-핫 인코딩을 적용하면, 각 과일이 독립적인 변수로 취급되어 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
Word2Vec: 단어 간 유사도를 고려하여 단어를 벡터로 표현합니다. 단어 임베딩의 대표적인 예시로는 Word2Vec, GloVe, FastText 등이 있습니다. 이러한 기법들은 텍스트 데이터를 학습하여 각 단어에 대한 고정된 크기의 벡터를 생성합니다. 이 벡터는 단어의 의미를 반영하도록 학습되며, 이를 통해 유사한 의미를 가진 단어들은 벡터 공간에서 가까이 위치합니다.
데이터를 Word2Vec 모델을 이용하여 벡터로 변환하는 방법은 다음과 같습니다.
- 데이터 전처리 데이터를 Word2Vec 모델에 적용하기 전에, 불필요한 문자나 특수문자 등을 제거하고 단어들을 토큰화하여 준비합니다.
- 모델 학습 학습을 위해 데이터를 준비한 후, Word2Vec 모델을 학습시킵니다. 모델 학습을 위해서는 학습 데이터가 필요합니다. 학습 데이터는 일반적으로 대량의 텍스트 데이터가 필요합니다.
- 벡터화 모델 학습이 끝나면, 각 단어는 고정된 크기의 벡터로 표현됩니다. 이렇게 변환된 벡터를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
- 분석 및 모델링 벡터화된 데이터를 이용하여 분석 및 모델링을 진행합니다. 이 때, 벡터화된 데이터를 이용하여 각 단어 간의 유사도를 계산할 수 있으며, 이를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
위와 같이 Word2Vec 기법을 적용하여 데이터를 벡터로 변환하고, 이를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
GloVe: 전체 말뭉치에서 각 단어의 동시 등장 빈도를 고려하여 단어를 벡터로 표현합니다. 단어 임베딩을 학습하기 위해서는 대량의 텍스트 데이터가 필요합니다. 이 데이터를 이용하여 모델을 학습시키고, 각 단어에 대한 벡터를 생성합니다. 이후 생성된 벡터를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있을 것입니다.
GloVe(Global Vectors for Word Representation) 기법을 이용하여 데이터를 벡터로 변환하는 방법은 다음과 같습니다.
- 데이터 전처리 데이터를 GloVe 모델에 적용하기 전에, 불필요한 문자나 특수문자 등을 제거하고 단어들을 토큰화하여 준비합니다.
- 동시 등장 행렬 생성 GloVe 모델은 단어의 동시 등장 행렬(co-occurrence matrix)을 이용하여 단어 간의 상호작용을 파악합니다. 따라서, 동시 등장 행렬을 생성해야 합니다.
- 모델 학습 동시 등장 행렬을 이용하여 GloVe 모델을 학습시킵니다. 이 때, 학습 데이터는 대규모의 텍스트 데이터가 필요합니다.
- 벡터화 모델 학습이 끝나면, 각 단어는 고정된 크기의 벡터로 표현됩니다. 이렇게 변환된 벡터를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
- 분석 및 모델링 벡터화된 데이터를 이용하여 분석 및 모델링을 진행합니다. 이 때, 벡터화된 데이터를 이용하여 각 단어 간의 유사도를 계산할 수 있으며, 이를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
위와 같이 GloVe 기법을 적용하여 데이터를 벡터로 변환하고, 이를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
학습을 위해 적절한 데이터를 준비하셨다면, 이러한 단어 임베딩 기법을 적용하여 데이터를 벡터로 변환해보세요. 이후 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있을 것입니다.
단어 임베딩 기법을 적용하여 데이터를 벡터로 변환하는 방법은 여러 가지가 있습니다. 그 중에서도 가장 대표적인 방법은 Word2Vec이라는 기법입니다. Word2Vec은 단어를 고정된 크기의 벡터로 변환하며, 이를 통해 단어 간의 유사도를 계산할 수 있습니다.
Word2Vec은 CBOW와 Skip-gram 두 가지 모델을 제공합니다. CBOW 모델은 주변 단어들을 이용하여 중심 단어를 예측하는 방식으로 학습하며, Skip-gram 모델은 중심 단어를 이용하여 주변 단어들을 예측하는 방식으로 학습합니다. 이 두 모델 중에서 어떤 모델을 선택할지는 데이터의 특성에 따라 다르므로, 적절한 모델을 선택하는 것이 중요합니다.
Word2Vec을 이용하여 학습을 진행하면, 각 단어는 고정된 크기의 벡터로 표현됩니다. 이렇게 변환된 벡터를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다
4. 시퀀스 레이블링
개체명 인식: 문장에서 인물, 장소, 조직 등의 개체명을 인식합니다. 시퀀스 레이블링(Sequnce Labeling)은 시퀀스 데이터에서 각각의 요소에 대한 레이블을 예측하는 작업입니다. 이는 자연어 처리 분야에서 많이 사용되며, 예를 들어 개체명 인식(Named Entity Recognition), 음절 단위의 형태소 분석, 문장 분류 등에 활용됩니다.
의도 분류: 문장의 의도를 분류합니다. 시퀀스 레이블링을 위해서는 레이블링된 훈련 데이터가 필요합니다. 이 데이터를 이용하여 모델을 학습시키고, 새로운 시퀀스 데이터에 대한 레이블을 예측합니다.
감성 분석: 문장의 긍정/부정/중립적인 감성을 분석합니다. 시퀀스 레이블링 모델은 보통 Conditional Random Field(CRF), Hidden Markov Model(HMM), Recurrent Neural Network(RNN) 등의 알고리즘을 사용합니다. 이러한 알고리즘들은 각각의 특징을 가지고 있으며, 텍스트 데이터의 특성에 따라 적절한 알고리즘을 선택하여 사용해야 합니다.
학습을 위해 적절한 데이터를 준비하셨다면, 이러한 시퀀스 레이블링 기법을 적용하여 데이터의 각 요소에 대한 레이블을 예측해보세요. 이후 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있을 것입니다.
시퀀스 레이블링(sequence labeling) 기법을 이용하여 데이터의 각 요소에 대한 레이블을 예측하는 방법은 다음과 같습니다.
- 데이터 전처리 데이터를 시퀀스 레이블링 모델에 적용하기 전에, 불필요한 문자나 특수문자 등을 제거하고 단어들을 토큰화하여 준비합니다.
- 레이블링 각 단어에 대해 미리 정의된 레이블을 부여합니다. 이 때, 레이블은 해당 단어가 어떤 의미를 가지는지를 나타내는 정보입니다.
- 모델 학습 레이블링된 데이터를 이용하여 시퀀스 레이블링 모델을 학습시킵니다. 이 때, 학습 데이터는 대규모의 텍스트 데이터가 필요합니다.
- 예측 모델 학습이 끝나면, 새로운 데이터에 대해 예측을 수행합니다. 이 때, 예측된 결과는 해당 단어의 레이블입니다.
- 분석 및 모델링 예측된 결과를 이용하여 분석 및 모델링을 진행합니다. 이 때, 예측된 결과를 이용하여 각 단어 간의 관계를 파악할 수 있으며, 이를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
위와 같이 시퀀스 레이블링 기법을 적용하여 데이터의 각 요소에 대한 레이블을 예측하고, 이를 이용하여 분석 및 모델링 과정에서 더욱 정확하고 유의미한 결과를 얻을 수 있습니다.
시퀀스 라벨링


Speech 와 마찬가지로 Text Tuning word로 테스트 시퀀스 데이터라고 할 수 있습니다. 그리고 시퀀스 데이터에 라벨링을 할 수 있다는 것은 비단 자연어 처리뿐만 아니라 생물학(유전자) 등도 활용 가능한 범용적인 기술이다.

즉, 전기와 같이 순차적 데이터인 텍스트의 POS를 라벨링하거나 청크(구)를 파악하는 문제가 시퀀스 라벨링의 예라고 할 수 있다.

그리고 라벨링을 하고 분류로 풀 수 있어야 하고, NLP에 있어서는 아주 짧게 자체적으로 품사를 수리할 수 있기 때문에 앞의 단어의 품과 뒤에 품사를 모두 보고 각각의 품사를 분류해야 하고, 이후에 구현이 되고 할 수 있다. 그래서 필요한 것은 시퀀스 모델이다.
확률 모델
히든 마르코프 모델

HMM은 Markov 가정에 의해 가까운 N-1개 단어의 품사를 보고 현재 단어의 품사를 근사하는 방법이다. 규정된 원리를 식으로 보는 것보다 곰팡이로 보는 것이 더 편한데,

HMM이 완성되면 나란히 품사 DT다음에 관사 the 가맹점,반대관사 a가 펼쳤을 때 등이 세워지게 된다.
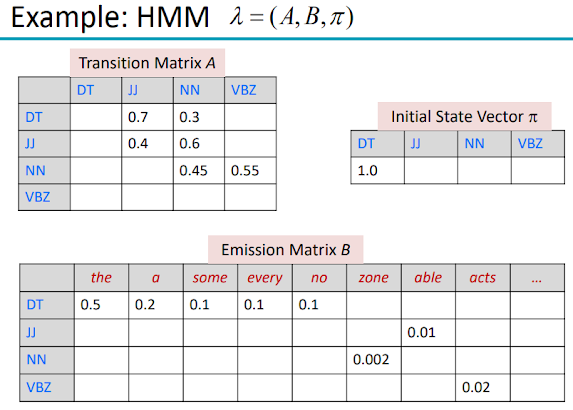
실제로 구현을 지켜보면서 테이블 형태로 재생을 메모리에 저장하게 된다. (Python에서는 defaultdict 자료구조를 주로 사용한다.)

이러한 방법은 자전거로 같이 가능한 한 모든 품사의 테니스를 구함으로써 하나하나 라벨링을 할 수 있습니다. 징이 품의 숫자만큼(ex. 45개), 문장이 길수록(ex. 10단어) 연산량이 기하급수적으로 많아진다. (예. 45^10 = 34,050,628,916,015,625)
그래서 개발된 것이 Viterbi Algorithm 이다. 이 운동의 목적은 마찬가지로 모든 경로의 확률을 계산하여, 이 과정에서 다른 경로에서 계산된 결과를 재사용할 수 있도록 합니다. ( 동적 프로그래밍 )
아래는 HMM을 구현한 툴킷이다.
- HTK(Cambridge Univ.) : http://htk.eng.cam.ac.uk/
- Matlab용 Mendel HMM 도구 상자: http://www.math.uit.no/bi/hmm/
- NLTK(자연어 툴킷) : http://www.nltk.org/
구문 및 구문 분석
※ 파싱은 분석과 시각적 의미로 사용되며, 특히 구문을 분석할 때 파싱 이란 말을 주로 해야 합니다.

구문은 교환법칙이 멍청한 수학처럼 행동하는 어순이 문제는 다른 의미를 가진 문제입니다. 그래서 구문은 단순한 차원이 아닌 좀 더 차원의 데이터로 간주해야 하며, 구문을 표현하는 개념이 바로 구성요소 와 종속성 이 있다.
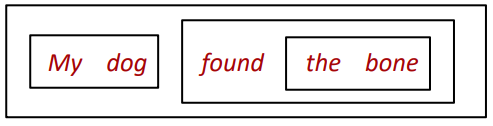
constituency 는 의미상 밀착한 단어들을 그룹화하는 개념이다. (단위 : 구성요소)

반면 의존성 은 단어간 충격을 표현한 개념이다. (morphological/syntactic/semantic) 예를 들어 형태론적인 개념에서 She는 have/has를 일정하게 유지할 수 있음으로 인상을 찌르고 할 수 있다.
※ 선거구, 종속성의 개념 정도만 기억해 두자.

이중 중 의존성 자료 구조가 어순에 자유로워 ML에도 주로 사용되는 자료 구조이다.
Chunk는 언어학에서 '구'의 개념보다는 작은 단위이고, (앞으 수식어는 포함시키되, 후의 수식어는 제외시키는 개념) Base NP(혹은 NP chunk)라고 합니다.

텍스트 청크는 문장에서 모둔 청크를 찾는다. 그리고 청킹을 추출하기 위해 위치표시 시퀀스 라벨링을 할 수 있다.
※법률상 NP 청킹의 F1점수는 96%, 텍스트 청킹은 94.13%로 사용되고 있다. (CoNLL 데이터)
그동안 이런 부분적 파싱을 넘어서 전체 파싱을 했다면 큰 전자 사전이 필요하다. 근래에 이 사전을 개발하는 것 자체에 상당한 자원이 필요하다. 최근에는 이런 사전이 없어도 DNN을 활용하면 NLP를 실천할 수 있는 시대가 되지만, 연구 데이터의 의존도가 매우 높아진 학습 데이터에 없는 데이터에는 즐거움이 빤히 없어진다. 그래서 모든 단어의 정보를 포함한 전체 구문 분석에 대해 알고 있어야 합니다.

한 작은 단위의 파싱부터 페이지. dependency parsing은 정보를 주는 서명에서 정보를 받는 서명으로 arc를 이어주는 것이다. 이런 관계를 트리로 표현하는 것이 Dependency Tree(D-tree)라 한다. 이 때 옆으로 아크가 방전지아래 사영한 나무라고 할 수 있는 척추,

위 그림과 같이 문장이 복잡해 아크가 발생하는 문장은 비투영한 포인터를 부족하고, 분석에 어려움을 겪는다. 참고로 영어보다 한글이 비투영인 경우가 훨씬 많다.
이제 파싱을 하는 방법을 해야 하지만, 파싱은 크게 2가지로 볼 수 있다.
첫번째는 아주 전통적인 방법인 문법 기반 파싱 인데, 이런 파싱은 언어 전문가가 아니면서 짧게 작업하고, 기존의 실무도 그렇게 좋지 못했다.
최근에는 Data-driven parsing 방법을 주로 도입한다. 데이터 기반 파싱에는 그래프 기반 모델 과 전이 기반 모델 이 있다.
본보기에서는 그래프 기반 모델은 건너뛰고 전환 기반 모델에 집중한다.

전환 시스템 은 현재 구성을 계속해서 변경(전환) 해서 단말 구성에서 종료되는 시스템이다.

구성 은 스택/버퍼/아크 세트라는 데이터 구조로 구성된다.
- stack : LIFO 특성을 원하는 자료 저장 구조(↔ queue)
- buffer : 마지막 단어를 기억하는 저장 공간이다. (queue로 구현)
- arc set : arc로 회로 기판의 튜플을 원본 으로 하는 세트
※ 이니셜 : 버퍼에 완전히 빠져있는 상태, 터미널 : 버퍼가 비어있는 상태

Transition-based parsing 은 위치를 언급했듯 단말 구성에 도달하면 문장의 분석을 끝맺고 할 수 있고, 그 결과를 D-tree로 출력 해야 한다. 중요한 것은 어떻게 초기에서 말단까지 도달하게 접점인데, 이 때 최소한의 행동을 최대한 적게 사용 하여 도달하게 해야 한다는 것이다. 이 때 도킹의 조치를 선택 할 수 있는 Oracle(분류자)이 했으면 결과를 계속할 수 있었다면, 이 Oracle을 Machine Learning 이 대신하게 된다.

위 그림은 transition-based parsing을 위한 표기법을 보여줍니다. (니브레 2003)
위 표기법에서는 4개의 동작(이동/축소/오른쪽 호/왼쪽 호)이 존재한다. 예제를 살펴보자.

현재 Arc set은 텅 비어 있고, Stack에는 ROOT만 들어 있다. (ROOT는 가상의 단어이다.)
ROOT는 가상의 단어이기 때문에 왼쪽/오른쪽 원호 동작은 해결할 수 없습니다. 지난 스택에도 텅 비어 있고 볼 수 있는 입체적인 버퍼에 있는 단어를 시프트 동작을 통해 스택에 담을 필요가 있다.

그래서 경제를 스택에 담아냈다. 일단 각 개념의 종속성을 계산할 수 있다고 가정하면, 경제와 뉴스, 가지고 있던 ... 타 종속성을 파악한 후 뉴스→경제로 왼쪽 아크 가 만들어진 후 스택에서 경제적을 빼야 한다.

2번째 자신감이 완성됐다. (C2) 다음 동작은 뉴스를 스택에 최대 종속성을 파악한 후

했다와 뉴스의 왼쪽 아크가 방전야 한다.

반복하면
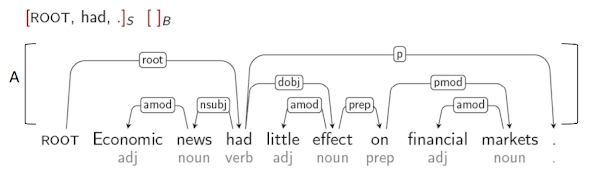
---------↑ 설명이 부족함. 강의 다시 볼 것.-----------------
이렇게 해서 분석이 이루어졌는데, 이 모든 것이 사람이 직접 오라클의 역할을 잘했다고 여겨진다.
'플러그인 링크 리더' 카테고리의 다른 글
| {특집} 혁신적인 기업이 진화를 거듭하는 방법과 그것이 중요한 이유 [물건 팔던 마케팅, 이젠 기업의 성장 동력, 어떤 물건 만들지 결정하는 혁신의 축으로 파괴 시대의 마케팅 전략] (0) | 2023.06.20 |
|---|---|
| 슈퍼볼 광고 속 현대 [경기보다 더 재미있다 : 숨겨진 지하철 공간의 재활용, 디아블로 IV 체험존] (0) | 2023.06.20 |
| '수익'을 소개합니다. (1) | 2023.06.06 |
| 얼리 어답터가 하는 일과 뜻이 궁금해요 [PHONEQUAD는 새로운 몰입형 핸즈프리 사진 및 라이브 비디오 세계를 엽니다] (0) | 2023.06.04 |
| 챗GPT 플러그인 사용법 총정리 (0) | 2023.06.03 |
| 올해 비즈니스 성공 필수 요소는 콘텐츠 제작 및 워크플로우 개선 (0) | 2023.06.03 |
| 돈 버는 재미 머니랩 (0) | 2023.05.26 |
| 250억 써도 혹평…잘 나가는 K콘텐트 [SF만 고전하는 이유] (0) | 2023.05.26 |



