Google Bard 구글 바드 한글 무료 사용법
기존에는 바드를 미국/영국에서만 지원하였지만, 이제는 우리나라에서도 VPN 없이 사용이 가능해졌습니다. 오늘은 구글 바드 AI 챗봇을 신청하고 사용하는 방법에 대해서 알아보도록 하겠습니다.
|
구글 바드란?
|
구글 바드는 OpenAI의 챗GPT와 유사한 대화형 챗봇으로 구글의 방대한 양의 데이터로 학습된 AI 챗봇입니다.
머신러닝을 사용하여 텍스트를 분석하여 그 기반으로 대답을 예측하고 인간의 말을 모방합니다.

|
구글 바드 AI 챗봇 사용방법
|
우선 바드의 공식 사이트는 아래에 있습니다. 아직까지 베타버전이기 때문에 waitlist 대기자를 추가한 다음 허가가 되면 사용이 가능합니다.
하지만 허가도 5분 안에 빠르게 메일이 옵니다.

구글 바드는 ChatGPT와 비슷한 대화형 AI 프로그램입니다. ChatGPT와 비슷하기 때문에 여러 논란도 많은데요,
구글을 떠난 제이콥 데블린 구글 전 엔지니어는 구글이 바드를 개발하기 위해 분명히 챗GPT의 데이터를 사용했을 것이라고 주장했습니다. 하지만 제 생각은 어떤 기술이 나왔을 때에는 그것을 가장 잘 활용하는 기업이 승자라고 생각하기 때문에 경쟁 관계에서는 법적인 부분이 아니고는 벤치마킹을 할 수 있다고 생각합니다. 그런 부분이 인류의 발전에도 좋지 않을까요
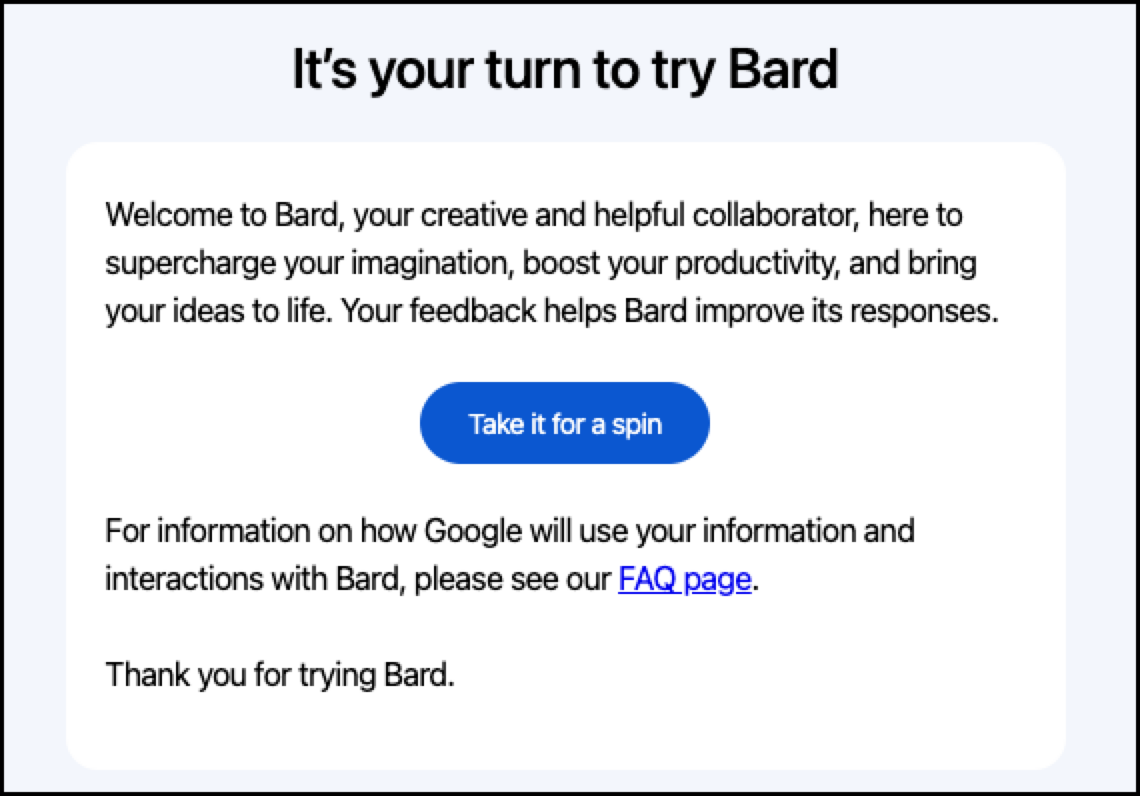
바드를 사용할 수 있는 차례라고 메일이 왔습니다. "Take it for a spin" 을 클릭해서 바드를 사용하러 가줍니다.
|
바드의 뜻
|
바드는 음유시인이라는 뜻을 가지고 있는 단어입니다.
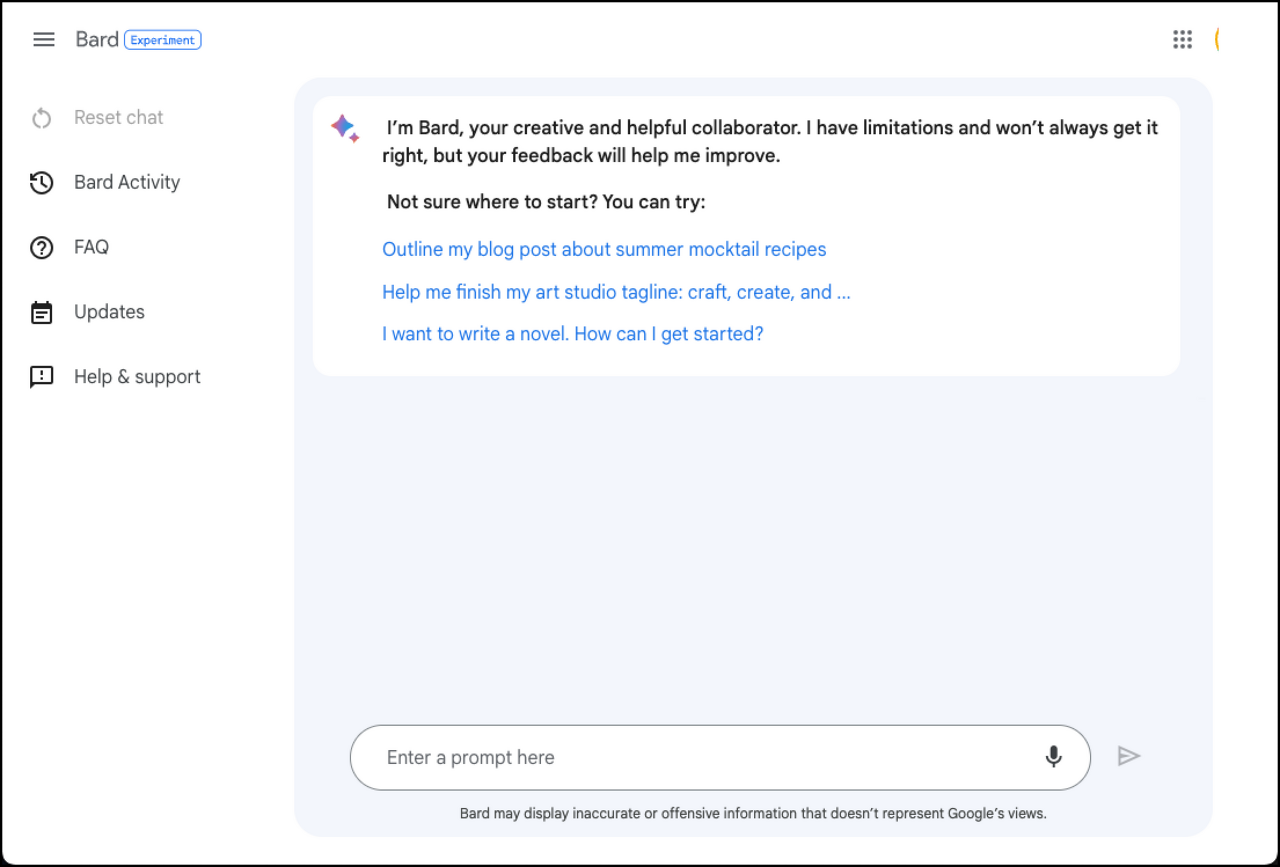
아직까지 한글 버전이 정식으로 출시되지 않았기 때문에 브라우저의 번역기 기능을 사용해서 대화를 해 나가야됩니다.
아래 대화를 입력하는 부분을 프롬프트 라고 합니다. 일종의 명령어라고 보시면 되는데요, 여기에 내가 원하는 정보를 입력해 주시면 됩니다.
바드에 아래와 같이 명령어를 입력해 보았습니다.
결혼식 신랑 입장곡 5곡 추천해주세요

결혼식에서 사용할 수 있는 신랑, 신부 입장곡을 추천해 줍니다.
Elvis Presley의 "Can't Help Falling in Love" 이 고전적인 사랑 노래는 신랑의 입장 노래로 시대를 초월한 선택입니다. 가사는 사랑에 빠지는 내용을 담았고, 멜로디는 로맨틱하면서도 경쾌하다.
Bruno Mars의 "Marry You" 이 노래는 결혼의 흥분에 관한 것입니다. 가사는 기쁨과 기대로 가득 차 있으며, 음악은 경쾌하고 재미있습니다.
John Legend의 "All of Me" 이 노래는 아름다운 사랑의 선언입니다. 가사는 진솔하고 진솔하며, 음악은 로맨틱하면서도 감동적이다.
Harry Styles의 "Adore You" 이 노래는 부부가 나누는 깊은 사랑과 애정에 관한 노래입니다. 가사는 달콤하고 로맨틱하며 음악은 부드럽고 감미롭습니다.
Whitney Houston의 "I Will Always Love You" 이 상징적인 러브송은 신랑의 입장곡으로 클래식한 선택입니다. 가사에는 부부가 나누는 영원한 사랑에 대한 내용이 담겨 있으며, 음악은 파워풀하고 감동적이다.
답변을 정말 빠르게 해줍니다.
챗GPT와는 속도가 차이가 나는 것 같습니다. 아무래도 자체 클라우드 서비스도 가지고 있는 구글이다 보니 서버 부분에서도 더 빠른 응답을 해주는게 아닐까 싶습니다.
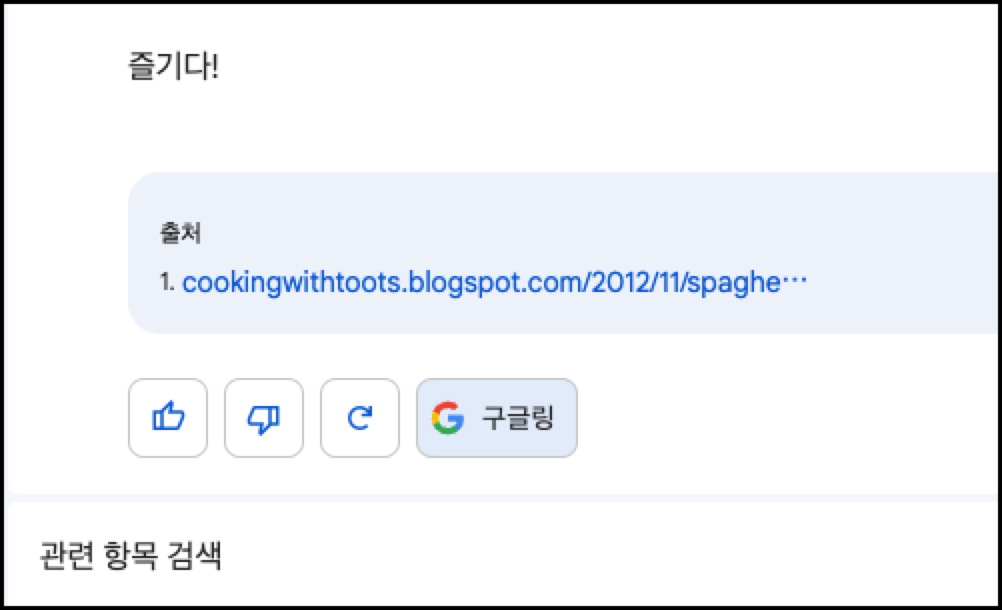
그리고 내 질문에 대한 다양한 검색어들도 추천해 주고, 어디서 가져왔는지 출처도 알려주게 됩니다. 어떻게 보면 내가 검색한 결과를 구글에서 한번 더 걸러준 느낌입니다. 당연히 내가 검색한 결과를 구글에서 바로 검색할 수 있게 구글링 기능도 제공하고 있습니다.
답변에 대해서 평가를 해주면 아마 구글에서 개선을 더 할 수 있지 않을까 싶습니다. 앞으로도 chatgpt와 bard의 대결 구도가 기대가 많이 됩니다. 사용자입장에서는 다양한 양질의 서비스를 다 받아볼 수 있어서 정말 좋은 대결 구도입니다.
Overview │ AI튜터 개발을 통한 스마트러닝 플랫폼 성장 도모
EdTech 산업 시장이 확대되면서, 개인 맞춤형 콘텐츠에 대한 소비자들의 요구도 커졌습니다. 그러나 다양한 교육 서비스와 학습 콘텐츠 모델이 필요한 시장의 요구와 달리, 실제로 그것을 커스터마이징할 수 있는 기능은 찾기가 쉽지 않습니다. AI튜터 개발은 물론, 독자적인 콘텐츠를 만들 수 있는 플랫폼이 필요했습니다.
NER 기술은 관련 주제나 개념 및 키워드를 식별하기 위해 기사나 연구 논문, 책과 같은 대량의 텍스트를 분석하는 데에 사용할 수 있습니다. 이는 특정 주제 영역이나 학습 목표에 맞게 조정된 교육 자료를 큐레이팅하고 구성하는 데에 도움이 될 수 있습니다.
우리 고객사는 독자적인 교육 콘텐츠를 제작하기 위해 NER을 통해 Text의 구문을 해석하고 비슷한 콘텐츠가 아니라 학생 맞춤형 콘텐츠를 제작할 수 있는 기반을 도입하고자 했습니다.
Problem │ AI튜터를 위한 NER 자동화부터 작업자 관리까지
미니게이트는 독자적인 교육 콘텐츠 및 서비스 확보를 위해 과학, 인문 등의 분야에 대해 대규모 인공지능 학습용 데이터 구축 작업이 필요했습니다.
이 프로젝트의 특이한 점은 플랫폼 커스터마이징이 필요했다는 것입니다. 데이터 구축을 위한 전문 인력은 보유하고 있으나, 해당 데이터를 가이드에 맞게 가공할 수 있는 플랫폼이 필요했죠. 데이터 구축을 위한 대부분의 기능을 추가 개발하는 작업이 필요했습니다.
동일한 데이터를 단계별로 다른 태스크에 옮겨가며 새로운 레이블을 덧붙이는 기능 구현이 최우선 과제였습니다. 또한, 일부 데이터에 대해서는 레이블 값을 CSV에 입력 후 업로드했을 때 플렛폼에 레이블 값이 표시되도록 하는 기능이 추가되어야 했죠.
또한 미니게이트의 프로젝트 내용에 맞는 플랫폼 활용 및 운영 관련 가이드를 요청하셨습니다. 해당 가이드를 토대로 고객사에 작업자 정산/관리/통계 확인/데이터 업로드/배정/조정 등 프로젝트 운영 및 관리 등 플랫폼 활용 교육을 진행하기로 협의했습니다.
데이터헌트는 보유하고 있는 SaaS 플랫폼을 고객사가 희망하는 형태로 커스터마이징하는 프로젝트에 돌입했습니다. 최종적으로, 고객사에 최적화된 기능을 커스터마이징한 뒤 이를 고객사가 보유한 라벨러에게 교육하는 형태로 협업이 시작되었습니다.
Solution │ NER 가공 3단계 구축 및 AI튜터 개발을 위한 플랫폼 활용 교육
미니게이트에서 데이터헌트 측으로 요청한 NER 3단계는 아래와 같은 과정으로 이어집니다.
Step 1. 텍스트 개체 인식
Step 2. 텍스트를 외국어로 번역
Step 3. 개체 인식 및 번역 과정 검수
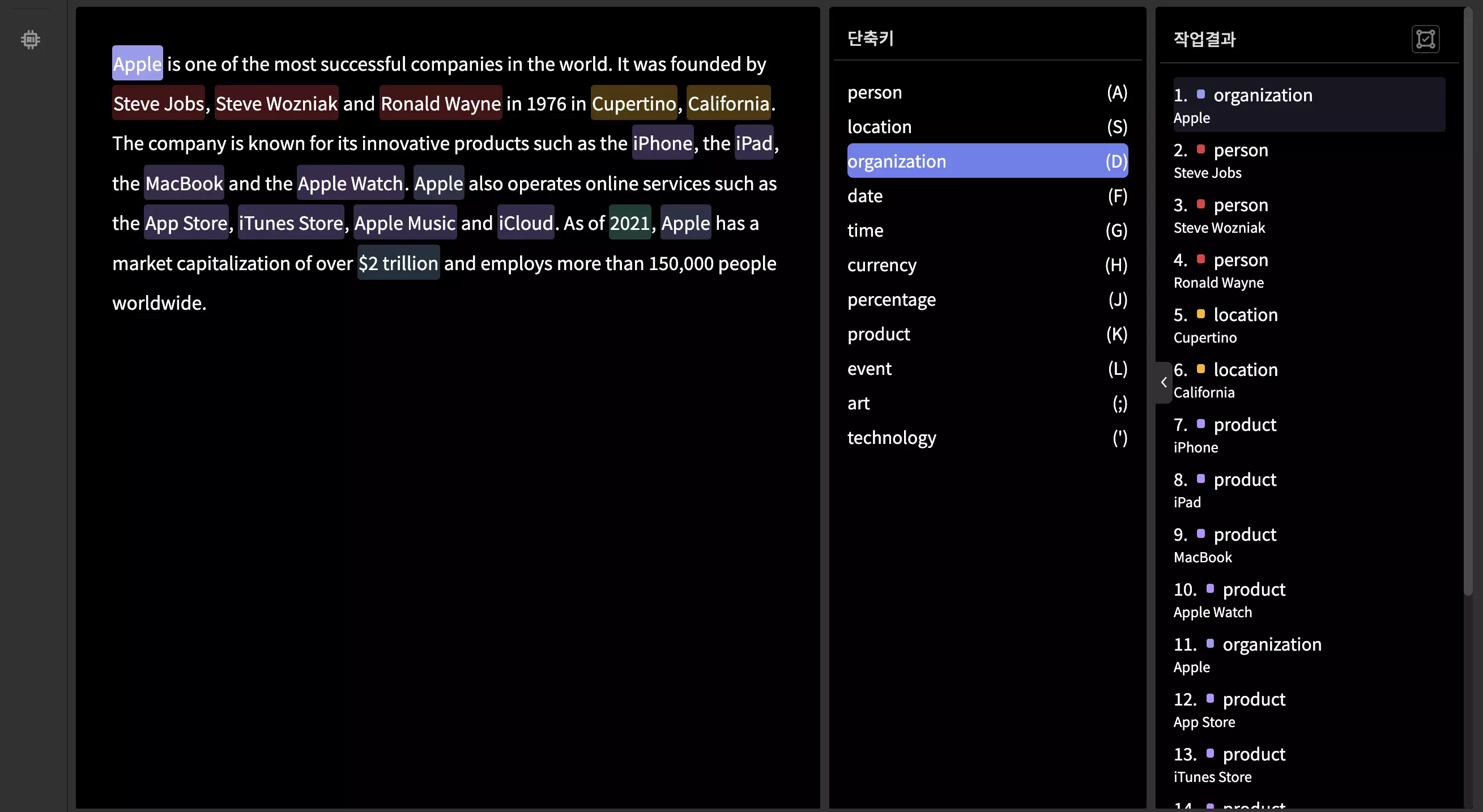
실제 작업에 대한 예시 (오토라벨링)
또한, 프로젝트에 참여한 작업자 정산과 진척률 관리, 반려 비율 등을 관리할 수 있는 기능을 제공하여 워크플로우를 최소화하고 퀄리티 고도화할 수 있도록 설계했습니다.
커스터마이징이 완료된 후에는 고객사와의 꾸준한 커뮤니케이션을 통해 완성된 플랫폼에 대한 피드백과 개선 작업을 진행했습니다. 커스터마이징을 통해 기능을 구현하는 것에 못지 않게, 플랫폼의 안정성 역시 중요한 문제이기 때문입니다.
플랫폼을 구축한 뒤에도 이에 대한 질의 및 개선 요청 사항에 대해 실시간으로 대응해야 합니다. 데이터헌트에서는 고객사 질의를 줄이기 위해 비대면 플랫폼 가이드 교육을 추가로 진행하였습니다.
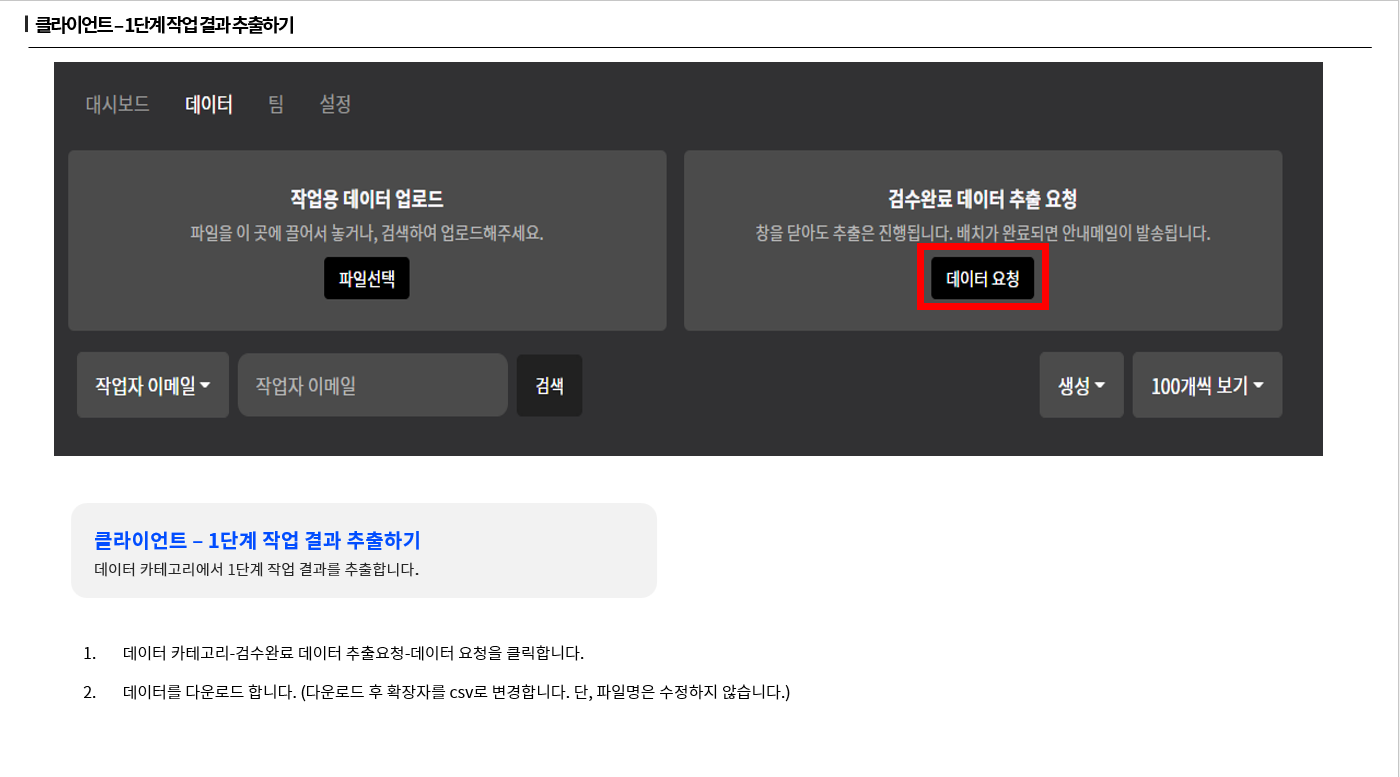
고객사에서 데이터헌트 측으로 요청한 NER 3단계는 텍스트 개체 인식, 외국어 번역, 개체 인식 번역 및 검수 과정으로 이루어집니다.
Result │ AI튜터 개발 및 NER 오토라벨링 Platform
긴 프로젝트를 통해 마침내 SaaS 플랫폼 커스터마이징이 완료되었습니다. 라벨러가 데이터를 입력하면 기초과학/인문 등에 대한 텍스트 데이터 구성 및 단어에 대한 개체 인식이 시작됩니다. 이후, 텍스트(문장)에 대한 외국어 번역이 이뤄집니다. 마지막으로 개체 인식 및 외국어 번역에 대한 검수로 정확도를 끌어올립니다.
플랫폼 커스터마이징이 끝난 후에도 고객사의 개선 요청 사항을 적극 반영하여, 기존에 있었던 기능의 편의 제고 및 UX 개선 작업이 진행되었습니다. 실제 크라우드워커 및 관리자들의 목소리에 귀 기울인 덕분에, 운영·관리 면에서 편의성과 효율성이 크게 상향되었습니다. 고객사 담당자는 물론, 프로젝트 담당자 역시 크게 만족할 수 있는 성과를 낼 수 있었습니다.
음성전사/STT로 심리 분석 데이터 분석
멀티모달 감정분석 데이터 구축

Overview │ 감정 분석을 위한 음성전사 기술의 가능성
음성전사 기술은 음성 언어의 자동 분석을 통해 감정을 해석할 수 있는 잠재적 능력을 가지고 있습니다. 텍스트 데이터에서 의견의 긍정/부정을 자동으로 감지할 수 있게 됩니다.
예를 들어, 콜센터 관리자는 고객 서비스 통화를 전사함으로써 상호 작용의 감정을 분석하고 개선이 필요한 영역을 식별할 수 있게 되는 것입니다. 많은 통화에 부정적인 감정이 있는 경우, 콜센터 관리자는 근본 원인을 조사하고 고객 만족도를 개선하기 위한 조치를 취할 수 있습니다.
동국대학교 AI소프트웨어융합학부는 미래 사회를 주도하는 AI융합역량을 갖춘 융복합 인재 양성에 앞장서고 있습니다. 최근 학부 내 산학협력단 및 연구원들은 심리상담 챗봇 시스템 구축 사업에 착수했습니다. 영상 및 텍스트 데이터에 포함된 발화자의 감정을 분석하여 대답해주는 심리상담 챗봇 시스템을 구축하는 것이 주요 목표였습니다.
Problem │ 종합적인 감정 분석 모델 개발을 위한 음성전사 데이터 활용
고객사는 심리 상담 멀티모달 감정 분석 모델 개발에 필요한 학습 데이터를 구축해야 했습니다. 멀티모달 감정 분석 모델을 통해, 사용자가 전달하는 텍스트를 분석하고 대답해주는 심리 상담 챗봇 시스템을 구축할 계획이었습니다.
심리상담에서 음성전사 및 멀티모달은 감정을 감지하고 상담 세션의 효과를 평가하기 위해, 상담자의 목소리 톤과 피치를 분석하는 데에 사용할 수 있습니다. 예를 들어 이 모델이 내담자의 어조와 음조 변화를 분석하여 감정 상태의 변화를 추적한 데이터를 토대로 상담 기술의 효과를 평가할 수 있게 되는 것이죠.
이외에도 음성전사 멀티모달은 취업 면접이나 대중 연설과 같은 다른 맥락에서 감정과 행동을 분석하는 데에 사용할 수도 있을 것입니다. 머신러닝 모델은 목소리와 얼굴 표정을 분석하여 행복, 슬픔, 분노, 불안과 같은 감정을 감지하고 개인의 감정 상태에 대한 분석을 제공합니다.
Solution │ 음성전사/멀티모달 기술로 심리상담 데이터셋 구축
멀티모달 특성상 여러 인터페이스를 통해 정보를 파악해야, 해당 문장에 대해 보다 정확한 감정 분석을 할 수 있습니다. 이에 이번 프로젝트에서는 데이터 가공 전, 텍스트 데이터와 연관된 시청 자료를 제공 받기로 협의했습니다. 문장의 텍스트 뿐만 아니라, 영상 데이터를 함께 비교하면서 대화의 앞뒤 문맥과 발화자의 감정을 파악할 수 있는 데이터셋 구축이 가능하게 되었습니다.
데이터헌트는 이렇게 일했습니다
데이터헌트가 작업한 Semantic segmentation 분류는 다음과 같습니다.
음성전사를 통한 semantic segmentation
speech to text
text_intent
발화자의 의도를 표시 / 총 26개의 클래스로 구성
대주제
대화의 주제를 입력 / 총 15개의 클래스로 구성
소주제
사전 정의된 클래스 없이 작업자의 주관적인 판단에 따라 입력한다. 단, 시나리오 내용에 어긋나지 않고 최대한 범주와 연관성 있게 작성한다.
CML 감정
CML 연구소에서 만든 6가지 감정으로 구성되어있다. 레이블링 시 비슷한 단어가 아닌, 정의된 6가지 값으로만 레이블링 한다.
감정1
CML 감정보다 더 구체화 된 감정으로 총 21개 Pair와 1개의 “중립” 단일 속성으로 구성 되어있다. 단, 중립의 사용은 가능한 지양한다.
감정세기
감정 1에 대한 세기를 태깅한다. 중립의 경우 “2”로 입력한다.
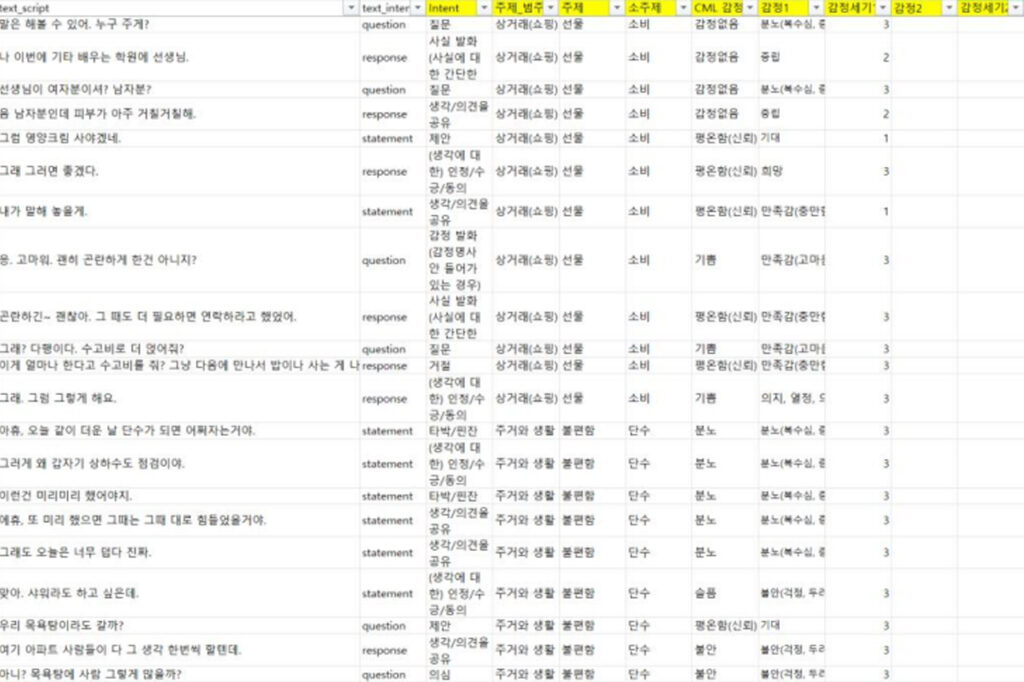
음성전사 멀티모달 기술로 더 정확한 감정분석 학습데이터 구축 실제 사례
작업자들은 먼저 텍스트 대화문에 해당하는 영상을 시청합니다. 그리고 대화문의 영상과 스크립트를 비교합니다. 각 항목별 클래스를 확인하여 대사에 가장 적합한 9개 항목에 대한 레이블링을 진행합니다.
주제/소주제는 작업자의 주관에 따라 입력하는 영역입니다. 단, 대화의 시나리오와 대범주에 어긋나지 않는 선에서 입력할 수 있습니다. 하나의 대사에 복합적인 감정이 반영되어 있어, 단일 감정으로 분류하기 어려운 경우도 있을 것입니다. 이럴 때에는 ‘감정 2’ 컬럼에 태깅하는 방식으로 복합적인 상황에도 유연하게 대응할 수 있도록 구체화했습니다.
Result │ 99.995% 정확도를 기록한 멀티모달 음성전사 데이터
이 프로젝트에서 데이터헌트는 약 79,346개 문장에 대한 멀티모달 음성전사 작업을 마쳤습니다. 이 중 370개에 대해서만 피드백 후 수정 작업이 이루어졌으며, 정확도는 99.995%를 기록했습니다.
텍스트 가공 프로젝트는 기계적으로 단순 반복 작업을 이행하는 것으로 이해하기 쉽습니다. 하지만 이번 프로젝트는 대화 세트에서 주제/소주제를 추론해야 하는 미션이 있었습니다. 또한 감정에 대해 5개의 태깅 항목을 입력해야 합니다. 이에 대화문의 텍스트만 보고 판단하는 것이 아니라, 관련 영상 자료를 함께 시청하면서 보다 정확한 태깅값을 입력할 수 있도록 하였습니다.

text script와 대화 영상을 통해 대화의 성격을 8가지로 분석/분류합니다.
음성전사 작업 중에서도 난이도가 어렵고 복잡한 프로젝트였지만 이례적인 정확도 99%를 달성했다는 점에서 고객사에서도 큰 환영을 받았습니다. 일반적인 텍스트 감정 분석 프로젝트는 2-3개 정도의 감정값만을 태깅하여 학습 데이터로 사용합니다. 하지만 데이터헌트는 학습 데이터의 품질을 향상시키기 위해 8개의 속성값을 태깅함으로써, 훨씬 더 정교한 데이터를 구축해냈습니다.
마음이 건강한 대한민국을 위해
대학(원)생 심리·정서 지원 실태 조사 보고서에 의하면, 대학 상담센터 상담사 1명이 맡는 재학생 규모가 최대 1,505명에 달한다고 합니다. 가장 부담이 적은 대학도 상담사 1인당 212명의 재학생을 상담해야 하죠. 지속적인 상담이 중요함에도 불구하고, 열악한 여건 탓에 극단적인 위험군에 속하는 게 아니고서는 10~15회 이상의 상담을 받기도 어렵다고 합니다.
우리 고객사는 멀티모달 감정 분석 모델을 개발하여 심리 상담에 대한 인력 리소스를 줄이고자 했습니다. 앞으로도 인공지능 기술이 사회 현안 문제를 해결하고, 또 개선을 돕기를 바랍니다.
Polyline으로 정확한 Computer vision 데이터 구축
정확한 자율주행 학습 데이터
스트라드비전

Overview │ Computer vision 자율주행 데이터 구축의 핵심, Polyline
자율주행 솔루션에는 Lidar를 사용하는 것이 일반적이었습니다. 하지만 카메라 기반 인식 솔루션인 테슬라 비전의 등장으로 업계에 새로운 바람이 불고 있죠. Computer vision 자율주행 솔루션의 핵심은 Data Annotation 작업에 있습니다. 카메라가 수집한 데이터에는 기계가 보고 있는 것을 이해할 수 있도록 주석을 달아주는 것이죠. 여기에는 다른 자동차, 보행자, 교통 표지판, 차선 표시와 같은 객체를 식별하고 데이터 세트에 Polyline 레이블을 지정하는 작업도 포함됩니다.
Computer vision 자율주행 솔루션을 개발하는 것은 운전자의 안전성과 편의성을 증진하기 위해 필수적인 관문입니다. 또한 카메라에 기반한 자율주행 솔루션은 기존의 방식에 비해 비용이 저렴하다는 점에서 주목 받고 있습니다. 그 외에도 테슬라는 Computer vision이 Lidar 기술 방식보다 혁신적인 이유를 여러 번 설명한 적이 있었죠.
우리 고객사는 다양한 차종에 카메라용 소프트웨어를 공급하는 기업입니다. 그 외에도 SoC 플랫폼에 솔루션을 도입하는 등 다양한 기술적인 도전을 이어가고 있습니다. 카메라 기반 자율주행 시대의 서막이 오르면서, 자율주행 차량용 솔루션 개발을 준비하고 있었죠.
Problem │ Polyline 레이블링 방식으로 자율주행 데이터 구축하기
Computer vision 자율주행 솔루션을 개발하기 위해서는 대량의 인공지능 데이터셋 구축이 필요합니다. 특히 차선 및 도로, 야간 환경에서의 데이터 등 각종 Edge Case에 대한 데이터 구축이 필요한 상황이었죠. 더 나아가 국내 도로 데이터 외에도 일본이나 미국 등 해외 도로 데이터셋을 구축하는 작업이 필요했습니다.
구축 데이터를 활용한 소프트웨어를 통해 고객이 사용하는 플랫폼 내에서 높은 정확도로 자율주행을 할 수 있는 것이 프로젝트의 최종 목표였습니다. 주행 경로 상의 교통 방향이나 기타 장애물에 대해 자율적인 인지가 가능해진다면, 완전 자율주행 대중화도 멀지 않았다고 생각했죠.
데이터헌트와 고객사가 협의한 데이터 레이블링과 가공 방식은 아래와 같습니다.
고객사가 요청한 데이터 레이블링
국내/해외(일본, 미국, 유럽)에서 수집한 데이터야간 등 특수 환경에서 수집된 데이터
멀티캠을 통해 수집된 데이터
Pre-labeling된 데이터의 추가 가공
데이터 가공 방식
차선: 이미지 데이터 내 도로의 차선 Polyline 레이블링
도로 가장자리: 도로의 경계 레이블링
기타 표식: 도로 내에서 차선으로 혼동될 수 있는 부분들을 표기하는 작업
진행 당시, 고객사로부터 600장 가량의 방대한 가이드를 전달 받았습니다. 대량의 Polyline 레이블링 데이터를 구축해야 하는 사업인만큼, 작업하는 라벨러들에게 전달할 내용은 명확하고 간결해야 할 필요가 있었죠. 또한 가공에 대한 정책 변경이 잦아 해당 내용을 작업자들에게 빠르게 전파해야만 했습니다.
Computer vision 데이터 구축 중에서도 난이도 높은 프로젝트인 만큼 작업자 투입과 숙련에 유의하는 것이 중요한 미션이었습니다.
Solution │ Data Annotation을 통한 Computer vision 데이터 구축
분량이 많은 데이터 가공 프로젝트일수록, 높은 정확도로 데이터를 가공하는 것이 중요합니다.
차선 작업
Line Detection을 위해 도로 내 차선을 레이블링하고 차선의 생김새 및 종류를 분류, 차선의 너비에 맞춰 작업
Polyline 작업 방식으로 Data Annotation
소실점 정하기 > 작업 범위 확인 > 차선 그리기 > 너비 조정 > 차선 분류 > 겹치는 부분 작업
분류: 도로 모양(5종), 차선 라인 수(3종), 위치(4종), 특이 케이스(2종), 색상(4종) 등을 각각 선택하여 분류
도로 가장자리
차량이 주행할 수 있는 도로의 경계를 레이블링하고, 경계의 종류를 분류
Polyline 작업 방식으로 Data Annotation
소실점 정하기 > 작업 범위 확인 > 도로 경계 표시 > 분류 > 가려진 부분 작업
분류: 위치(4종), 종류(비콘, 벽면 등 19종)
기타 표식
차선으로 혼동될 수 있는 요소를 제거하는 작업으로, 도로 내 화살표나 글자, 도형 등을 제거하는 작업
Polygon 작업 방식으로 Data Annotation
작업 범위 확인 > 기타 표식을 Polygon 선택 작업 > 차선과 겹치는 부분 수정 작업
작업 순서 및 검수 기준
(작업자) 1차 작업 > (검수자) 검수 진행 및 작업자에게 피드백 및 재작업 요청 등을 반복 > (PL) 검수를 마친 작업물에 대해 세부 작업 내용 조정 > (PM) 납품 전 최종 검토
차선 작업의 경우, 차선의 생김새부터 종류 등이 매우 다양합니다. 도로 가장자리는 차선 작업보다 경계의 종류가 복잡했습니다. 특히, 해외 도로의 경우 작업난이도가 높아 세심한 Polyline Labeling 작업이 필요했습니다.
데이터헌트는 일반적으로 원활한 커뮤니케이션과 작업 관리를 위해 국내 라벨러와 협업합니다. 해외 데이터에 대해서 생소한 케이스가 있을 수 있기 때문에, 특별히 집중할 필요가 있었죠. 사전에 작업 투입 시 교육을 진행하는 것은 물론, 샘플 테스트 등을 진행했습니다. 특히, 난이도가 어려웠던 차선/경계 등의 Polyline 레이블링 등 Data Annotation 업무에 대한 집중 교육을 실시했습니다.
Result │ 30만 장의 Polyline, 오류율은 5% 이내

정확한 polyline이 완벽한 자율주행의 미래를 앞당길 수 있습니다
최종적으로 고객사에서 요청한 내용을 포함해, 데이터헌트가 프로젝트 내에 완수한 Data Annotation 성과는 아래와 같습니다.
고객이 요청한 데이터 레이블링
국내/해외(일본, 미국, 유럽)에서 수집된 데이터
야간 등 특수 환경에서 수집된 데이터
멀티캠을 통해 수집된 데이터
유럽/미국/일본/국내 자율주행 데이터를 모두 포함한 약 30만 장의 자율주행 데이터 구축
납품 전 데이터는 4단계 이상의 작업/검수 과정을 거쳐 고객사 품질검수 자체 기준 (오류율 5% 이내)를 모두 통과
데이터 가공 방식
차선: (데이터(이미지) 내 도로의 차선 polyline 레이블링
도로 가장자리: 도로의 경계 Polyline 레이블링
기타 표식: 도로 내에서 차선으로 혼동될 수 있는 부분들을 Polygon 레이블링
인공지능과 사람이 함께 하는 일
해당 프로젝트는 방대한 정책과 가이드, 다양한 정책 변동 사항에 대해 실시간 대응이 필요한 프로젝트였습니다. 동시에, 대규모 작업자가 투입되어야 하기 때문에 라벨러와 퀄리티 관리 측면에서 까다로운 점이 많았습니다. 효율적인 업무를 위해 프로세스와 가이드를 정립하는 과정을 먼저 거쳤습니다.
특히 이번 기회를 빌어 데이터헌트 내부적으로 AI Prelabeling 및 자동 교육 테스트 등을 도입해 작업자 교육 과정을 정례화했습니다. 앞으로도 명확한 기준을 통과한 작업자들을 확보할 수 있을 것입니다.
어려운 업무에도 빠르게 따라와 주신 작업자 분들과 데이터헌트 내부 인력들에게 이 자리를 빌어 감사의 인사를 전하고 싶습니다.
이번 프로젝트를 통해 데이터헌트는 고난이도의 자율주행 프로젝트에 대한 교육 및 프로젝트 이행을 마친 작업자 600명 확보하였습니다. 앞으로 유사 프로젝트 시 신속하게 투입하여 보다 빠르고 정확한 Polyline 및 Polygon 데이터 구축이 가능할 것이라고 확신합니다
데이터바우처 성공사례- 쿠아탑스
3D모델링으로 디지털 트윈 구축
쿠아탑스

스타트업 쿠아탑스가 개발 중인 ‘해양 메타버스’는 AI 기반 3D모델링 수중 생물을 생성하는 플랫폼 서비스를 지향합니다. 쿠아탑스는 디지털 수족관 구축을 위해 3D데이터 구축 계획을 세웠습니다. 하지만 국내에서 마땅한 기술 협업을 찾지 못하던 과정에서, 데이터바우처 지원사업이라는 좋은 기회를 얻게 되었죠. 데이터바우처를 인연으로 데이터헌트와 첫 사업을 시작하게 된 쿠아탑스는 현재까지 순조롭게 메타버스 수족관 개발을 진행하고 있습니다.
데이터바우처 지원사업, 데이터헌트와 시작하세요!
데이터바우처 지원사업은 초기 중견기업 및 중소기업, 소상공인과 예비창업자들에게 데이터 구매 및 가공비용을 정부에서 바우처 형태로 지원해 주는 사업입니다. 데이터헌트는 2019년부터 4년 연속 공급기업으로 선정되었으며, 2020년에는 우수사례로 선정되어 데이터가공 업계에서 주목을 받기도 했습니다. 아래에서 데이터헌트와 협업한 수요기업의 실제 업무사례를 직접 확인해 보세요.
쿠아탑스가 말하는 데이터바우처 지원사업 성공사례
안녕하세요. 쿠아탑스에 대한 간단한 소개 부탁드립니다.
쿠아탑스는 국내 유일 해양 디지털 트윈 & 메타버스 플랫폼 기업입니다. 다만 디지털 수족관 비즈니스는 이미 해외에서 성행하던 사업입니다. 쿠아탑스가 비즈니스 모델 변경을 계획하던 당시도 이미 전 세계적으로 100군데 정도 만들어져있던 상황이었죠. 하지만 프로그래밍되어 반복된 움직임만 보여주는 물고기 객체는 소비자가 지속적으로 관심과 흥미를 보이기 힘든 구조였습니다.
디지털 아쿠아리움에 보다 다채로운 볼거리를 더하기 위한 방법을 강구하던 중 데이터바우처 지원사업의 수요기업으로 선정되었습니다. 이를 이용해 국내 해양 환경에서 국내 서식 어종의 실제 움직임 데이터를 수집하고, 3D데이터 구축 사업을 통해 물고기의 실제 움직임을 AI를 통해 구현하고자 했습니다.

데이터바우처를 통해서 보다 실감나는 디지털 아쿠아리움을 만들고 싶으셨다고요?
쿠아탑스가 ‘해양 메타버스’를 제작하기 위해 가장 먼저 시도한 것은 기술자를 찾는 것이었습니다. 국내에서 이를 가능하게 할 기술 인력을 찾는 것이 쉬운 일이 아니었죠. 먼저 회사 내의 직원들에게 IT 심화 과정 교육을 수료하도록 지시하여 내부 인력의 양성을 시도했습니다.
관상어 마니아가 ‘물 없는 수족관’ 스타트업 만들다… ‘쿠아탑스’ 창업기 인터뷰 보러 가기 (출처: 매일경제)
하지만 쿠아탑스가 꿈꾸는 ‘해양 메타버스’를 완성하기 위한 수준 높은 3D 에셋 데이터 제공이 가능한 기업은 많지 않았습니다. 있다고 하더라도 기술력의 수준이 만족스럽지 않은 정도라 쿠아탑스 입장에서도 고민이 많을 수밖에 없었죠.믿을 수 있는 파트너를 찾아 전전하던 중, 쿠아탑스와 데이터헌트가 만나게 되었습니다. 꽉 막혀있던 ‘해양 메타버스’의 청사진이 보다 명확해지기 시작했죠. 무엇보다 데이터헌트는 쿠아탑스가 만들고자 하는 AI 모델과 3D데이터 구축 사업에 대한 이해가 명확했기에 많은 도움을 받을 수 있었습니다.
데이터헌트의 데이터바우처 지원사업 성공 컨설팅
데이터헌트와 함께 데이터바우처 지원사업에 참여하셨을 때 어떤 도움을 받으셨나요?
수중생물의 3D데이터를 구축한다는 건 정말 까다롭고 어려운 일이거든요. 그런데 데이터헌트는 3D데이터를 구축할 수 있었어요. 이것 자체가 정말 큰 도움이 되었죠. 이를 통해 쿠아탑스의 AI 모델이 해양 생태계에 대해, 그리고 수중생물의 움직임에 대해 학습할 수 있었으니까요. 3D에셋 데이터는 국내에서 구축할 수 있는 기술력을 갖춘 곳이 많지 않습니다. 정말 실력있는 AI 인력을 갖추고 있는 곳이 아니라면 구현이 어려운 모델이었죠.
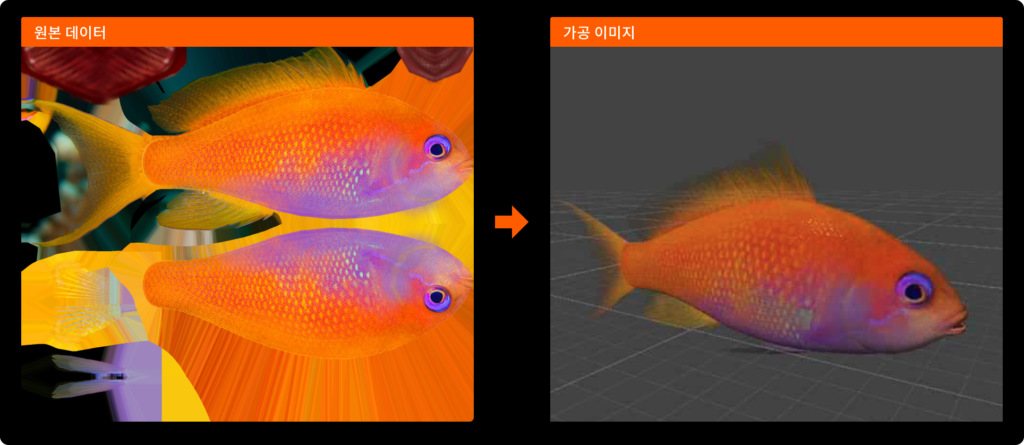
실제 해양생물 데이터를 활용하여 3D 모델링 가공한 자료
시간이나 작업량이 만만치 않은 비즈니스 모델임에도 불구하고 데이터헌트에서 많은 도움을 주셔서 즐겁게 협업할 수 있었습니다. 특히 쿠아탑스에서 구현하고자 하는 AI 모델에 대해 저희 엔지니어만큼이나 깊이 이해하려고 노력해주신 부분이 감명깊었죠. 모델 설계를 위해 어떤 데이터가 필요한지 구축 방안을 컨설팅해주시면서, 기반을 마련해주셨기에 지금의 ‘쿠아탑스’가 있었다고 할 수 있습니다.
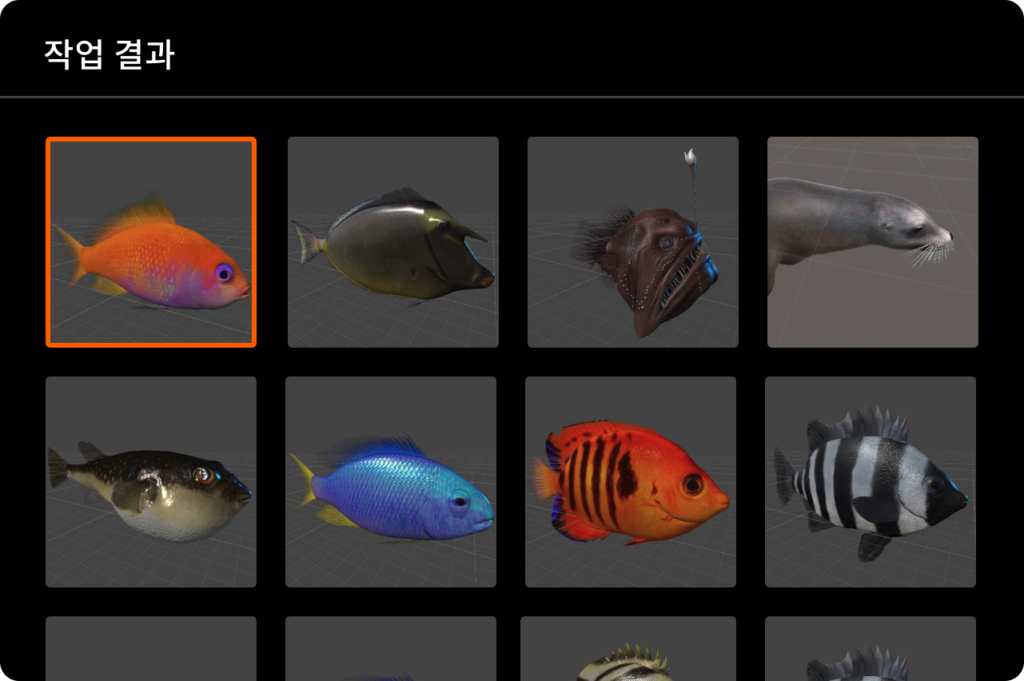
데이터바우처 성공사례 – 각종 해양생물 모델링
데이터바우처 지원사업 진행 과정에서 데이터헌트의 컨설팅 과정이 궁금합니다.
당시 데이터바우처 지원사업에 선정되기 위해 데이터헌트에서 다양한 컨설팅 제안을 보내주셨어요. 그 중 저희가 가장 핵심적으로 내세웠던 키워드는 바로 ‘디지털 트윈’ 정책입니다. 우리는 쿠아탑스의 3D 데이터셋이 디지털 트윈 정책과 적절하게 연계될 수 있다는 사실을 알았습니다. 이런 내용을 보고서 전반에 담아낸다면 데이터바우처 지원사업에 선정되기에 매우 유리한 조건이라고 생각했죠.
데이터바우처 공급 기업 선택할 때 ‘이것’만은 꼭 고려하세요
데이터바우처 지원사업에서 공급 기업 선정을 위해 많은 기업이 고민하고 계실 것이라 생각합니다. 수요기업의 입장에서 좋은 공급기업을 고르기 위해서는 실제 구현에서 디테일한 전문성을 가지고 있는 곳이 필요하다고 생각합니다. 수요기업의 사업을 깊게 이해하지 않는다면 불가능한 일이겠죠.
데이터헌트는 쿠아탑스의 사업과 AI모델에 대한 이해도가 굉장히 높았습니다. 구현하기 어려운 데이터였음에도 유능한 결과를 내주셨죠. 또한 데이터바우처 지원사업 선정 과정에 있어, 다년간의 노하우를 갖고 있어 큰 도움을 받았습니다. 쿠아탑스의 명확한 사업 방향성과 데이터헌트의 데이터가공 실력, 그리고 컨설팅 능력이 결합되어 성공적으로 데이터바우처 지원 사업을 마무리했다고 생각합니다.
쿠아탑스는 국내 영역뿐만 아니라 글로벌 진출을 목표로 서비스를 갈무리하고 있습니다. 3D데이터 서비스 구축이 완료되면 본격적으로 글로벌 진출을 도모할 예정입니다. 해외 시장에서 ‘AI 기반의 디지털 아쿠아리움’하면 떠오르는 기업이 되는 것이 목표입니다. 데이터헌트와의 합작품인 3D데이터 셋은 우리가 만든 자랑스러운 해양 메타버스 안에서 영원히 살아 숨 쉬겠죠.
데이터바우처 성공사례- 해피로봇
데이터바우처를 통해 무인주차 혁신

주차 공간 부족은 대한민국 뿐 아니라 전세계적인 고민거리 중 하나 입니다. 공간 자체가 부족하기 때문에 쉽게 해결하기 어려운 난제이기도 하죠. 데이터헌트의 고객사 해피로봇은 이런 문제를 AI와 로봇으로 해결하고 있습니다. 해피로봇이 어떻게 이 문제를 풀어가고 있으며 데이터바우처 지원사업과 데이터헌트를 통해 어떻게 도약하게 되었는지 소개합니다.
데이터바우처 지원사업, 데이터헌트와 시작하세요!
데이터바우처 지원사업은 초기 중견기업 및 중소기업, 소상공인과 예비창업자들에게 데이터 구매 및 가공비용을 정부에서 바우처 형태로 지원해 주는 사업입니다. 데이터헌트는 2019년부터 4년 연속 공급기업으로 선정되었으며, 2020년에는 우수사례로 선정되어 데이터가공 업계에서 주목을 받기도 했습니다. 아래에서 데이터헌트와 협업한 수요기업의 실제 업무사례를 직접 확인해 보세요.
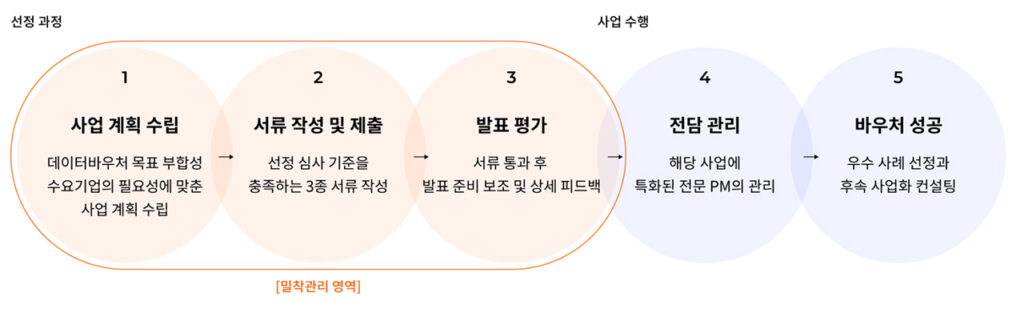
데이터바우처 지원사업으로 학습 데이터 구축하기
해피로봇이 데이터바우처 지원사업 수요기업으로 나서게 된 배경이 궁금합니다.
해피로봇이 개발하고 있는 시스템은 임베디드 AI(Embedded AI - 이하 EAI)입니다. 해피로봇의 EAI는 차를 옮겨주는 주차로봇을 목표로 설계되었습니다. 낮은 높이의 주차 로봇이 차를 들어서 옮기는 방식으로 주차 공간을 효율적으로 사용할 수 있는 혁신적인 방법이며, 이를 위해서는 로봇 안에 EAI 탑재가 꼭 필요합니다. 이 때 주차로봇이 원활하게 활동하기 위해서는 120mm의 여유 공간이 필요하다는 사실을 알게 되었어요. 실제 로봇이 바라보는 시선처럼 지면에 붙어서 차를 찍은 이미지를 수집하고, AI가 차량의 높이를 학습할 데이터가 필요했습니다. 데이터의 수집부터 가공까지 매우 어려운 난이도의 작업이었죠.

수집한 차량 이미지 데이터
해피로봇이 데이터바우처 지원사업 공급기업을 선정하는 과정에서 최우선으로 고려했던 것은 위에서 언급한 고난도의 데이터 수집 및 가공 작업이 가능한 지었습니다. 그리고 해피로봇이 개발하는 중인 EAI에 대한 이해 역시 필수적이었죠. 여러 공급기업과 제안을 나눈 끝에, 데이터헌트가 가장 적격이라고 판단되어 협업을 시작했습니다.
데이터바우처 지원사업을 수행하면서, 데이터헌트와 해피로봇이 지나온 여정에 대해 알려주세요.
해피로봇이 데이터헌트에 요청했던 학습 데이터는 수많은 차종에 대해서 높이를 측정하는 방식을 도출해야 하고, 로봇의 시선으로 사진을 촬영해야 했습니다. 이 미션을 클리어하기 위해 데이터헌트 AI 엔지니어님들께서 감사하게도 발 벗고 나서주셨어요.

해피로봇 데이터바우처 지원사업 당시 수집한 고화질 이미지 자료와 이를 가공한 자료
먼저 해피로봇이 개발할 AI에 대한 이해를 바탕으로 구축할 데이터를 정의해 주셨습니다. 그다음으로 주차장 바닥에서 사진을 찍어 데이터 수집 과정을 함께해 주셨습니다. 정말 어려운 미션이었는데 높은 화질의 이미지를 수집해 주시고 정확히 Annotation 해주셔서 AI 학습에 큰 도움이 되었습니다. 열정적으로 수행해 주신 덕분에 해피로봇이 개발하고 있었던 AI 학습을 성공적으로 마무리할 수 있었습니다.
해피로봇이 말하는 데이터바우처 지원사업 성공 전략
앞으로 해피로봇과 데이터헌트가 협업할 계획과 목표가 궁금합니다.
향후에도 해피로봇은 데이터헌트와 EAI 개발을 포함해 관련한 데이터 셋 구축을 위해 지속적으로 협업할 예정입니다. 데이터바우처 지원사업을 성공적으로 마무리한 인연을 기회로, 앞으로도 저희와 동행하겠다고 약속해 주셨으니까요. 해피로봇이 만들어 갈 ‘세상을 바꿀 로봇’, 그 주역에 데이터헌트도 함께할 것입니다.
이 글을 보시게 될 수요기업 담당자 분들께서도 서로의 혁신과 성장을 위해 함께할 수 있는, 데이터헌트와 같은 공급기업을 고르시길 바랍니다. 데이터바우처 지원사업을 인연으로 좋은 파트너를 만나실 수 있을 겁니다.

마지막으로 데이터바우처 지원 사업에서 공급기업을 선택할 때, 꼭 고려해야 할 점이 있다면 무엇인지 말씀 부탁드립니다.
AI 도입이라는 같은 목표 아래에서, 수요기업과 공급기업은 절대 분절된 업무를 하는 것이 아닙니다. 공동의 목표를 이루기 위해 협업하는 거죠. 그렇기에 수요기업이 개발 중인 AI 모델을 이해할 수 있는 분을 공급기업으로 만나야 합니다. 더불어, 수요기업의 모델을 실제로 구현하기 위해 해결해야 할 문제를 해결하기 위해 적극적으로, 열정적으로 노력해 주실 수 있는 기업과 함께하실 것을 추천합니다. 바로 데이터헌트와 같은 곳이죠.
'메타버스 뉴스레터' 카테고리의 다른 글
| 2023 웹 개발 테크트리 총정리 (3) | 2023.06.10 |
|---|---|
| 2023년 주목해야 할 6대 테크 트렌드는... 한국 딜로이트 그룹 [메타, 올해 기업이 주목할 ‘2023 트렌드 보고서’ 공개] (0) | 2023.06.07 |
| 오늘의 트렌드 키워드 [주말에 떨어지는 블로그 방문자. 대책은?] (1) | 2023.06.04 |
| 전문가들이 GPT-4를 활용하는 법 (0) | 2023.05.24 |
| 키워드로 본 금융IT Issue (0) | 2023.05.22 |
| AI 훈련용 빅데이터 2026년 고갈···문제점과 대책은? (0) | 2023.05.21 |
| 챗GPT 활용 방법 – 텍스트 표로 만들기 (기초편) (0) | 2023.05.21 |
| 미래 기술 모두 모았다 [CES 2023 키워드는 ‘MECCA’] (0) | 2023.05.21 |



