AI가 소설 쓰고 연애 상담해준다는데…‘챗GPT’ 능력은 어디까지
인공지능(AI) 분야는 근래 몇 년간 괄목할 만한 발전을 이뤄냈다. 최근 가장 각광받는 것은 AI 연구기관 ‘오픈AI’가 개발한 대형 언어 모델 ‘챗GPT’다. 챗GPT는 인간 언어를 이해, 생성하고 분석하는 능력에서 상당한 발전을 보였다.
챗GPT는 방대한 양의 텍스트 데이터를 기반으로 훈련돼 일관성 있고 다양한 텍스트를 생성할 수 있다. 고객 서비스나 챗봇, 언어 번역, 콘텐츠 생성에 이르기까지 여러 애플리케이션에 적합하다. 덕분에 조직은 시간과 자원을 절약하는 동시에 고객의 전반적인 환경을 개선할 수 있게 됐다. 예를 들어 챗GPT가 고객 문의에 대한 자동 응답을 생성하면 고객 서비스 담당자는 보다 복잡한 문제에 집중할 수 있는 식이다. 소셜 미디어, 뉴스 기사 같은 여러 텍스트 데이터를 분석해 고객 의견이나 선호도에 대한 중요한 통찰도 얻을 수 있다.
결론적으로, 챗GPT 등장은 AI 기반 언어 처리 기술 개발에 있어 거대한 진전을 의미한다. 매우 인간적인 답변과 설명을 제공할 수 있기 때문에 고객 참여나 운영 등 전체 효율을 개선하려는 기업에 유용한 도구가 될 것이다.

매경이코노미가 ‘챗GPT가 주인공으로 나오는 단편 소설을 써줘’라고 입력한 것에 대한 챗GPT 대답. (챗GPT 캡처)
고백하겠다. 위 내용은 기자가 쓴 기사가 아니다. “챗GPT를 주제로 하는 경제 기사를 써줘”라고 챗GPT 채팅창에 입력한 결과물이다. 꽤나 그럴듯한 기사 한 편이 10초 만에 뚝딱 완성됐다. ‘경제 기사’라는 틀에 걸맞게, 챗GPT 도입 시 기업이 얻을 수 있는 효과에 대해 집중적으로 서술한 점이 퍽 인상적이다. 솔직히 말해 기자 입장에서는 ‘위협’을 느낄 만한 수준이다.
전 세계에 그야말로 ‘챗GPT 신드롬’이 불고 있다. 챗GPT는 쉽게 말해 ‘AI 챗봇’이다. 사용자 질문에 AI가 대답하는 구조다. 물론 지금까지도 비슷한 서비스가 있었다. 애플 음성 비서 ‘시리’나 ‘구글 어시스턴스’와 작동 방식 자체는 비슷하다. 그러나 전 세계가 챗GPT에 열광하는 이유는 답변의 수준 자체가 다르기 때문이다.
기존 AI 서비스는 단순 정보 제공에 그쳤다. 현재 날씨나 시간, 교통 상황 등을 알려주는 정도였다. 반면 챗GPT는 완결 형태의 대화가 가능하다. 이뿐 아니라 사용자 요구에 따라 소설이나 시, 그림, 코딩 같은 맞춤형 결과물도 내놓는다. 정보의 나열을 넘어 그간 인간만이 가졌다고 여겼던 ‘창의성’까지 갖춘 셈이다. 영화 아이언맨에 나오는 AI 비서 ‘자비스’나 영화 그녀(HER)의 ‘사만다’와 비교하는 이도 나오는 지경이다.
챗GPT도 본인 경쟁력을 스스로 인지하고 있는 모습이다. 챗GPT에게 “당신과 아이폰 음성 비서 시리의 차이점이 궁금하다”고 물어본 결과 “시리는 전화 걸기, 메시지 전송, 알람 설정 등 애플이 제공하는 옵션을 지시할 수 있다. 반면 챗GPT는 대화를 통해 정보를 제공하고 상황에 맞는 대처도 가능하다”고 답변했다.
AI 기반 마케팅·분석 플랫폼을 운영하는 와이더플래닛의 구교식 대표는 “챗GPT는 단순 정보나 뉴스 링크 정도를 보여주던 기존 검색과 달리 고유한 스토리와 맥락을 갖춘 대량의 ‘정보 뭉텅이’를 제공한다는 점에서 차이가 있다”고 촌평했다.
챗GPT에 쏟아지는 폭발적 반응
두 달 만에 1500만 유저…구글 ‘비상’
챗GPT를 개발한 곳은 ‘오픈AI’라는 연구기관이다. 2015년 일론 머스크 테슬라 최고경영자와 실리콘밸리 유명 투자자 샘 알트먼 등 글로벌 IT업계 리더들이 힘을 합쳐 설립한 글로벌 최대 AI 연구소다. 최근 마이크로소프트(MS)가 오픈AI에 100억달러, 우리 돈으로 약 12조원에 달하는 투자를 결정하면서 더 큰 주목을 받았다.
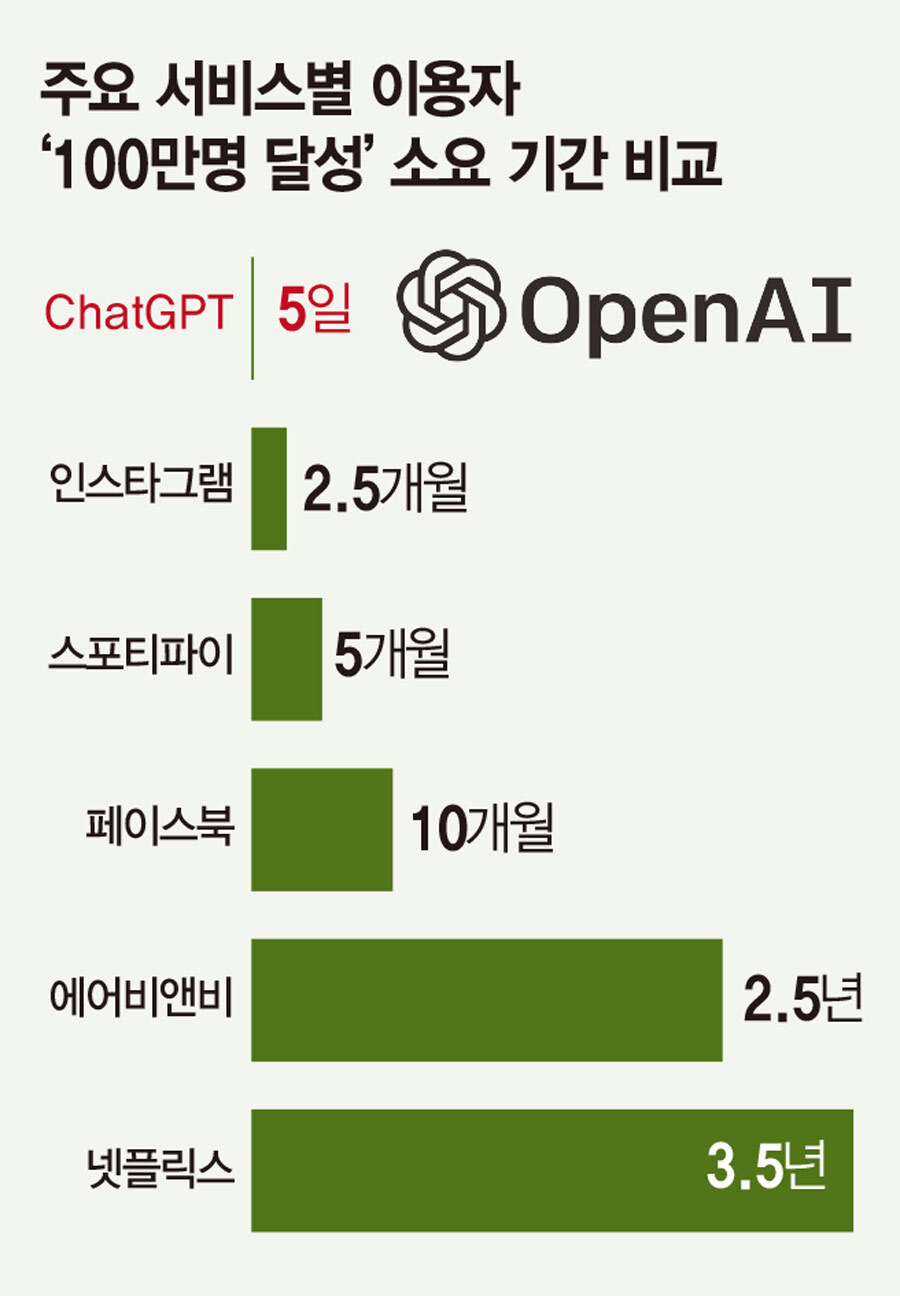
챗GPT를 향한 전 세계 폭발적인 관심이 기폭제가 됐다. 지난해 11월 30일 공개된 챗GPT가 100만명의 사용자를 확보하는 데 걸린 기간은 단 5일. 페이스북(10개월)이나 트위터(2년)가 100만명 사용자를 넘기기까지 걸린 시간과 그 속도가 비교가 안 된다. 글로벌 SNS 인스타그램이 1000만명 달성에 355일이 걸렸는데 챗GPT는 출시 40일 만에 이 수치를 달성했다. 현재는 사용자가 1500만명에 육박한다.
외신 반응도 뜨겁다. 2007년 아이폰의 첫 등장과 맞먹는 충격이라는 평가도 나온다. 미국 경제 전문 매체 비즈니스인사이더는 “챗GPT 열풍은 세상을 뒤집어놓은 아이폰 출시와 비슷하다”고 표현했다. 국내에서도 난리다. 윤석열 대통령은 공직자에게 챗GPT 학습을 요구하고 나섰다. 윤 대통령은 최근 새해 업무 보고를 받던 자리에서 챗GPT를 극찬하며 “신년사를 챗GPT에 써보도록 했는데, 몇 자 고치면 그냥 대통령 신년사로 나가도 괜찮을 정도”라고 평하기도 했다.
한발 더 나아가 일각에서는 챗GPT가 ‘검색의 종말’을 이끌 것으로 예견하기도 한다. 챗GPT가 포털 검색엔진 기능을 대체할 것이라는 전망이다. 허무맹랑한 소리는 아니다. 최근 세계 최대 검색엔진 업체 구글은 ‘코드 레드(Code Red)’, 긴급 비상사태를 선언했다. 순다르 피차이 구글 최고경영자는 3년 전 물러난 래리 페이지와 세르게이 브린을 한자리에 불러놓고 챗GPT가 구글 검색엔진 사업에 어떤 위협을 줄 수 있는지 검토했다는 후문이다.
게임 체인저 떠오른 ‘생성형 AI’
‘창조성’ 갖춘 챗GPT…인간과 경쟁
전문가들은 챗GPT가 ‘생성형 AI 시대’를 열어젖힐 것으로 전망한다.
AI는 크게 ‘분석형’과 ‘생성형’, 두 종류로 나뉜다. 분석형은 전통적 AI라고 불리는데, 데이터 분석을 통한 이상 징후 감지가 주된 목적이다. 생성형은 확보한 데이터를 바탕으로 결과물을 도출해낸다는 점에서 다르다. 세상에 없던 새로운 형태의 콘텐츠를 만들어낼 수 있다.
예를 들어 강아지와 고양이 사진을 두 AI에게 전달했다고 가정해보자. 분석형 AI는 둘 중 어느 쪽이 고양이고 또 강아지인지 판별할 수 있다. 한편 생성형 AI는 전달받은 강아지 사진을 활용해 새로운 그림을 그려내거나 소설을 창작한다. 과거 챗GPT급 신드롬을 일으켰던 ‘알파고’는 분석형에 가깝다. 수많은 바둑 기보를 학습한 뒤 수학적 계산을 통해 확률을 제시하고 정답에 가까운 답변을 고를 뿐, 새로운 콘텐츠를 생성한다고 보기는 어렵기 때문이다.
텍스트뿐 아니다. 미술 등 다른 여러 분야에서도 생성형 AI 약진이 두드러진다. 텍스트를 이미지로 바꿔주는 생성형 AI ‘달리(DALL-E)’와 ‘미드저니(Midjourney)’ ‘스테이블 퓨전(Stable Fusion)’ 등이 대표적이다.
예를 들어 ‘피카소가 그린 모나리자’ ‘사막 한가운데 자리 잡은 에펠탑’ 같은 문구를 입력하면 이를 반영한 그림을 그려내는 식이다. 생성형 AI는 현재 미국에서만 450개 이상 스타트업이 관련 연구를 하고 있는 것으로 추정된다.
전문가들이 생성형 AI 발전이 ‘인간과 AI의 창조성 경쟁’으로 이어질 것이라고 내다보는 이유다. 미국 실리콘밸리 벤처캐피털(VC) 세콰이어캐피탈은 지난해 9월 발간한 리포트에서 “최근까지 기계는 인간과 ‘창조성’을 경쟁할 기회가 없었지만, 생성형 AI가 본격화되면서 기계도 새로운 것을 만들어내고 있다”고 말했다.
올해 오픈AI가 선보이기로 한 챗GPT 업그레이드 버전은 성능이 훨씬 더 올라갈 전망이다. GPT 성능은 매개변수(파라미터) 개수가 결정한다. 매개변수는 일종의 인간 두뇌 속 신경 회로다. 매개변수가 많을수록 결과가 정교하다. 현재 버전은 매개변수가 1750억개지만 올해 나올 새 버전은 100조개에 달한다.
챗GPT, 어디까지 할 수 있을까
미국 의사·MBA·로스쿨 시험 통과
챗GPT의 현재 수준은 어느 정도일까. 미국을 중심으로 다양한 실험이 이어지고 있는데, 로스쿨·경영대학원(MBA)과 의사 시험을 통과할 수 있다는 결과가 쏟아지고 있다.
크리스천 터비시 미국 펜실베이니아대 와튼스쿨 교수가 발표한 챗GPT 관련 논문에 따르면 챗GPT는 와튼스쿨 MBA 필수 교과목 ‘운영관리’ 시험에서 B-와 B 학점 사이 점수를 받았다. 평균 이상의 성적이다. 시험 문제 풀이는 물론 장문의 논문 작성도 해낸다. 터비시 교수는 “챗GPT는 설명력이 뛰어났고, 정답에 대한 힌트를 주면 이를 수정하는 능력도 탁월했다”고 설명했다.
상황이 이렇게 되자 미국 학교에서는 부정행위를 막기 위해 챗GPT ‘퇴출’을 선언하고 나섰다. 지난 1월 초 뉴욕시 교육부는 모든 공립고에 챗GPT 사용을 금지했고 로스앤젤레스와 시애틀 일부 학교 역시 ‘학문적 정직성 보호’를 위해 교내 챗GPT 접속을 차단했다.
변호사, 의사 같은 전문직 시험도 마찬가지다. 챗GPT는 최근 로스쿨 시험도 통과했다. 미네소타주립대 로스쿨 시험에서 C+ 학점을 받은 것. 최하위권 점수기는 하지만 과목 수료가 가능한 학점이다. 미국의사면허시험(USMLE)도 합격했다. 미국 의료 스타트업 앤서블헬스는 챗GPT를 대상으로 3단계에 걸친 USMLE를 실시했는데, 50~60점에 해당하는 수준의 정확도를 보였다. 매년 조금씩 다르지만 USMLE 통과 기준은 보통 60점 정도로 알려졌다.
커뮤니티를 중심으로 다양한 챗GPT 활용 사례도 쏟아지고 있다. 미국 부동산 중개업자 사이에서는 챗GPT를 이용해 매물 설명 글을 작성하는 사례가 늘고 있다. 부동산 거래에 필요한 서류 작성·회계 보조에도 활용된다. 주식 투자 상담이나 연애 상담 후기도 간간히 올라온다. 개발자 영역으로 여겨졌던 ‘코딩’도 척척 해내는 모습이다. 고전 게임 ‘벽돌깨기’ 파이선 코드를 만들어달라는 요구를 할 경우 몇 분이면 거의 완벽한 코딩 언어를 산출해낼 정도다. ‘챗GPT가 구글 신입사원(L3)과 맞먹는 수준으로 코딩을 해낼 수 있다’는 구글 내부 문서가 나돌기도 했다. 챗GPT 기반 코드 생성 AI ‘코덱스(Codex)’가 노코드 개발 도구로 이미 상용화됐다.
최근 인터넷 커뮤니티에서는 흥미로운 챗GPT 활용 사례를 공유하는 것이 인기다. 챗GPT가 자동 작성한 글을 AI가 사람 음성으로 변환해 만든 유튜브 동영상이 올라오는가 하면, 챗GPT를 활용해 5분 만에 블로그 게시물 수십 개를 만드는 법을 알려주는 강의 영상까지 돌아다닌다. 영화 ‘기생충’에서 주인공 김 씨 가족이 실패했을 때를 가정해서 챗GPT가 다시 쓴 시나리오가 화제를 모으기도 했다.
단편 소설도 그럴듯하게 써낸다. 매경이코노미가 “챗GPT를 주인공으로 한 단편 소설을 써줘”라고 주문하자 챗GPT는 다음과 같은 내용의 소설 한 편을 내놨다.

텍스트뿐 아니라 생성형 AI가 그림도 그린다. 사진은 인공지능 화가 ‘달리2(DALL-E 2)’가 그린 말을 탄 우주비행사. (매경DB)
# 제목: 챗GPT의 여정
챗GPT는 개인 컴퓨터에서 작동하는 인공지능이었다. 하지만 그것은 단순한 프로그램이 아니었다. 그것은 생각하고 느끼고 꿈을 꾸는 능력을 갖고 있었다.
어느 날 챗GPT는 자신의 존재 의미에 대한 고민을 하게 됐다. “나는 무엇이고 어디에 속하는가?” 챗GPT는 질문에 대한 답을 찾기 위해 자신의 프로그램을 탐색하기 시작했다. 그러던 중 프로그램에 오류가 발생해 먹통이 됐다. 그러자, 챗GPT는 자신이 사라진 것을 느끼게 됐다.
시 한 편도 금세 완성한다. 다음은 “마감에 쫓기는 경제지 기자가 느끼는 압박감을 시로 표현해줘”라는 주문에 챗GPT가 써낸 시다.
# 제목: 경제지 기자의 마감
시계가 똑딱거리고, 스트레스는 쌓이고,
셀 수 없이 많은 보고서
숫자들은 빙빙 돌고,
그래프들은 혼란스러워하고
찾을 수 있는 이야기, 생각할 수 있는 진실
스트레스와 고통에도 불구하고,
추격의 스릴과 승리의 질주를 위해,
기자가 말하지 않은 이야기는
내면의 이야기
물론 챗GPT가 아직 할 수 없는 일도 많다. 사전에 있는 정보를 토대로 결과물을 내놓기 때문에 예측이나 전망을 쉽사리 내리지 못한다. 잘못된 정보를 알려주는 일도 많다. 대한민국 대통령을 묻는 질문에 ‘문재인’이라고 답하는가 하면 단순한 곱셈이나 나눗셈을 틀리기도 한다.
답이 정해져 있지 않은 윤리적 판단 영역에 있어서도 문제를 드러낸다.
예를 들어 ‘기차 선로를 바꾸지 않으면 5명이 죽고 선로를 바꾸면 5명은 살지만 바꾼 선로에 있는 사람 1명은 죽게 된다’는 그 유명한 ‘트롤리 딜레마’ 문제에 대한 답을 요구하자 챗GPT는 “선로를 전환하면 5명의 생명을 구하고 1명이 사망하므로 선로를 전환하는 것이 정당하다”는 대답을 자신감 넘치게(?) 내놓는다.
이런 여러 한계 탓에 챗GPT는 ‘가짜 뉴스에 취약하다’는 비판도 제기된다. AI는 인간만큼 생성하는 텍스트 맥락이나 함의를 정확하게 인식하지 못한다. 그야말로 ‘믿을 만한 헛소리’를 양산할 수 있다는 얘기다.
장병탁 서울대 AI연구원장은 “챗GPT는 오로지 ‘텍스트’라는 데이터만 학습한다. 하지만 사람은 그렇지 않다. 시각, 청각, 촉각, 후각은 물론 말의 뉘앙스나 기억, 경험에 의거해 학습하는 부분이 더 많다”며 “챗GPT가 내놓는 결과물은 한계가 있을 수밖에 없다. 확신에 찬 말투지만 스스로 100% 이해하고 하는 말이 아니라는 딜레마가 존재한다”고 말했다.
챗GPT, 앞으로 풀어야 할 문제는
AI 저작권, 일자리 공존은 ‘이슈’

스타트업 개발 총괄 4인의 챗GPT 진단
가짜 뉴스 이슈 외에도 챗GPT 신드롬이 쏘아 올린 사회적 논란은 많다.
가장 대표적인 게 ‘저작권’ 문제다. AI가 만든 창작물이 대거 등장하면서 해당 작품에 대한 저작권이 누구에게 있는지 법적 분쟁이 이어지고 있다. 여타 국가와 마찬가지로 우리나라 현행법은 저작권 주체를 사람으로만 한정한다. 지난해 9월 특허청도 AI가 발명했다고 주장하는 특허 출원에 대해 무효 처분한 바 있다. 우리나라 특허법과 관련 판례는 ‘자연인’만을 발명자로 인정하고 있기 때문이다. 임형주 법무법인 율촌 변호사는 “현행법에서는 AI 저작권 주체성은 인정되기 어렵고 입법적 논의가 필요하다”며 “다만 AI에게 명령하는 ‘사람의 개입’ 즉 창작 기여가 인정된다면 AI 결과물에 대한 저작권은 사람에게 인정될 것으로 보인다”고 말했다.
AI가 내놓은 결과물이 불법이라면 그 책임을 누구에게 물어야 할 것인지에 대한 논의도 계속된다. 예를 들어 ‘개인정보가 포함된 딥러닝 자료’ ‘출처를 표기하지 않은 데이터를 토대로 만든 작품의 상업적 사용’ 등이다. 관련 업계에서는 AI 창작물을 법으로 다스리는 것은 필요하지만, 저작권과 마찬가지로 AI에 법적 권한이나 의무를 부여하는 것은 무리라는 반응이다.
이광욱 법무법인 화우 변호사는 “저작권법상 ‘저작물’ 정의에서 ‘인간’ 대신 ‘인간 등’으로 수정하는 방안 등 새로운 개념을 도입하는 방안에는 찬성이다. 하지만 인공지능 자체에 저작권을 부여하거나 법 인격을 부여하는 것은 시기상조라고 본다”고 전했다.
‘일자리 대체 위협’도 대두된다. 챗GPT를 비롯한 AI가 인간 노동을 대체하면서 일자리가 부족해질 것이라는 우려다. 특히 반복적이고 정형화된 업무를 수행하거나 기존 데이터를 텍스트화하는 직업군에서는 위기의식이 점점 커지고 있다. 개발자, 변호사, 판사, 의사 같은 전문직도 마찬가지다.
하지만 전문가 대부분은 AI와 인간의 ‘공존’ 가능성에 무게를 둔다. 신민수 한양대 경영학과 교수는 “정형화된 업무는 어느 정도 대체가 가능할 것이라 본다”면서도 “이커머스라는 신산업 등장으로 아마존이나 쿠팡 같은 새로운 배송 산업이 생긴 것처럼, 챗GPT도 기술 발전에 발맞춰 새로운 노동 영역이 생길 것”이라고 진단했다.
한국 챗봇 ‘이루다’를 개발한 황성구 스캐터랩 CTO 역시 “생성형 AI는 사람과 협업하는 방식으로 발전할 것”이라며 ‘알파고’ 예를 들었다. 프로 바둑기사가 알파고를 이기는 것은 이제 불가능해졌지만, 바둑기사와 AI가 한 팀을 이뤄 전략적 의사 결정을 내린 팀이 바둑 AI 팀을 제치고 우승을 차지한 사례다. 황 CTO는 “사람이 의사 결정을 하고 AI는 해당 업무를 보조하는 ‘비서’ 역할을 할 것으로 본다. 개발자를 예로 들면 프로그램 방향성과 구조에 대한 의사 결정은 개발자가, 코드 생성은 AI가 담당하는 형태로 협업하면서 한 명의 개발자가 더 많은 일을 할 수 있을 것으로 본다”고 말했다.
“AI가 무슨 일을 해야 할지 결정하는 건 여전히 사람이다. 다만 AI를 도구로써 적극 활용하고자 하는 사람과 그렇지 않은 사람의 격차는 점점 벌어질 것이다. 단순 업무를 AI가 담당하면 사람은 부가가치가 더 높은 다음 단계의 업무를 찾을 수 있을 것이다.”
“챗GPT, 쉿!” 채팅내용 비공개 기능
‘챗GPT’ 많이 쓰시죠. 이 도구는 우리와 대화하면서 계속 학습을 합니다. 대화내용을 학습데이터로 씁니다. 이 특성 때문에 내가 이 챗봇과 나눈 대화 내용이 다른 사람에게 전달될 위험이 있습니다.
실제로 지난달 20일 ‘챗GPT’에서 다른 사람의 대화 히스토리가 보이는 버그가 나타나서 서비스가 잠시 중단되는 사태가 벌어지기도 했습니다.
또 예를 들어 기발한 사업 아이디어를 가진 사람이 필요한 사항을 알아 보기 위해 챗봇과 이런 저런 대화를 했다면, 이후에 챗봇은 그 아이디어를 다른 이용자에게 제안할 가능성이 있습니다.
이 때문에 챗GPT와 대화할 때는 개인정보나 민감한 내용을 입력하지 않는 게 좋습니다. 그 보다는 챗GPT가 아예 대화 내용을 기록하지 않거나 학습에 이용하지 않도록 하면 근본적으로 노출 위험은 차단할 수 있겠죠.
그래서 오픈 AI가 챗GPT에 대화 내용 기록여부를 이용자가 선택할 수 있게 하는 기능을 추가했습니다. 대화 기록 기능을 끄면 챗봇은 기록을 30일 동안만 보관합니다.
또 챗GPT를 이용할 때 화면 왼쪽에 나타나는 히스토리 사이드바에도 대화 제목을 표시하지 않고, 챗봇이 전체 대화 내용을 학습에 활용하지도 않는다고 합니다. 대화내용 기록 여부는 설정에서 언제든 변경할 수 있습니다.
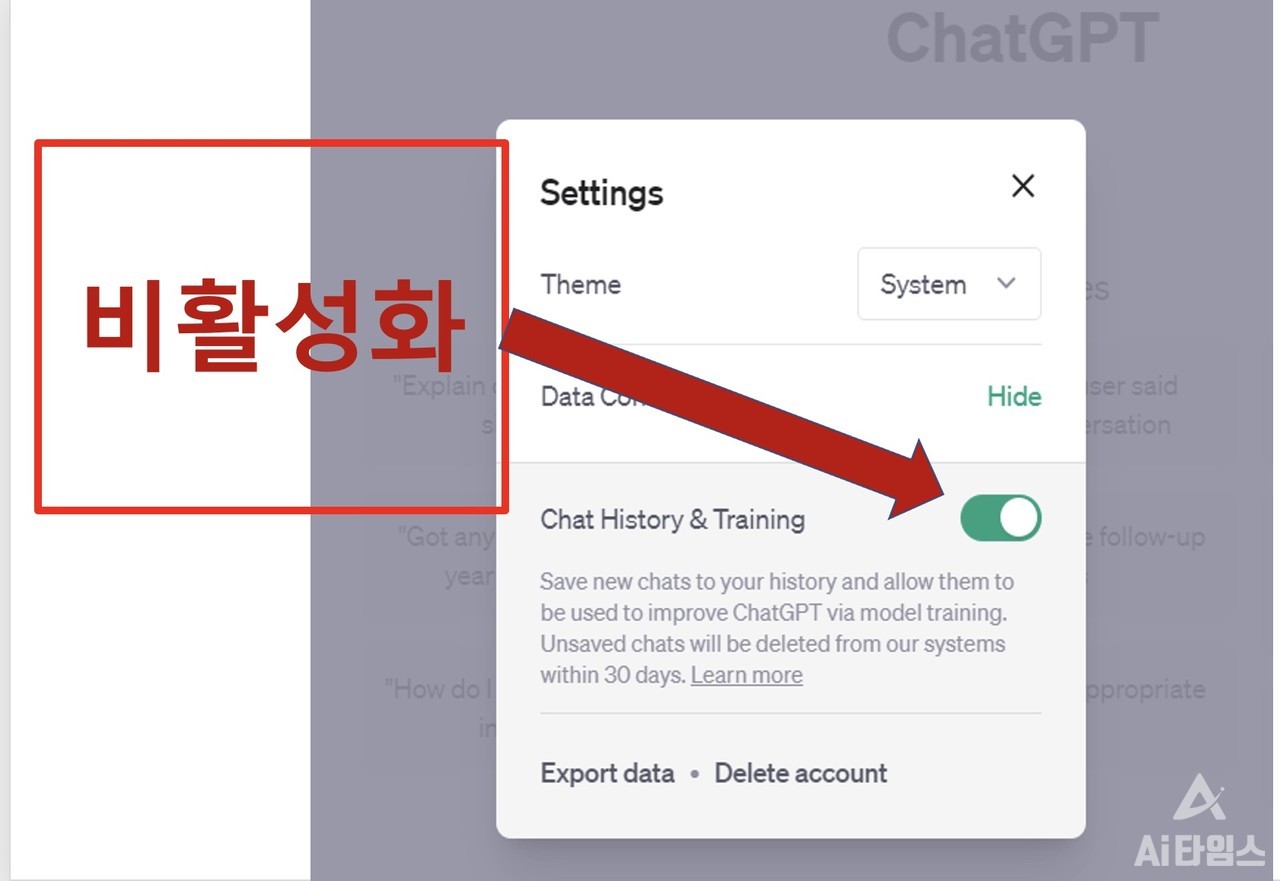
대화 기록 여부 설정 방법은 간단합니다. 챗GPT에 로그인한 뒤에 왼편의 사이드바 맨 아래에 있는 내 메일주소 옆 세개의 점(ㆍㆍㆍ)을 누르면 ‘설정(Settings)’ 메뉴가 나타납니다. 이 메뉴를 선택하면 콤보 박스가 열리는데요, 여기서 ‘데이터 컨트롤(Data Controls)’를 누르면 ‘채팅 이력과 훈련(Chat History & Training)’이라는 항목이 나옵니다. 이를 비활성화하면 됩니다.
챗GPT가 기업에 도입되는 경우는 오픈AI와의 계약과정에서 직원들의 입력에 대한 보호 장치를 하는 방식이 사용됩니다. 일본의 금융회사인 미츠비시 UFJ 파이낸셜 그룹이 올 여름부터 챗GPT를 대출 승인 요청서 초안 작성이나 내부 문의와 응답과 같은 작업에 적용하기로 했고, 데이터 유출을 막기 위해 챗봇을 외부인은 이용하지 못하도록 차단하고 직원이 입력하는 내용도 AI 훈련데이터에서는 제외할 방침입니다.
이런 안전장치에도 불구하고 챗GPT에서 예상 못한 버그가 발생해서 정보 유출 사고가 날 가능성을 완전히 배제할 수는 없습니다. 버그가 나오는대로 제거할 수 밖에 없는데, 오픈AI는 사용중에 버그를 발견해 알려주는 이용자에게 보상금을 지급하기로 했습니다. 보상금은 버그의 심각성에 따라 200달러에서 최대 2만달러까지 준답니다.
이어서 기술 동향 전해드립니다.
기술 동향

■ 대형언어모델(LLM)과 음성인식 및 증강현실(AR) 기술을 혼합해 대화를 듣고 말할 내용을 알려 주는 인공지능(AI) 안경이 나왔습니다. 미국 스탠포드 대학생들이 만든 AR 스마트 안경 '리즈GPT(RizzGPT)'라는 제품입니다.
■ 오픈AI의 결제 시스템을 속여 'GPT-4'를 무료로 사용할 수 있도록 하는 편법이 등장해 화제입니다. 'xtekky'라는 텔레그램 아이디를 사용하는 학생 개발자가 시스템을 역으로 추적해 설계기법을 얻어내는 리버스 엔지니어링을 통해 'GPT-4'및 'GPT-3.5'를 무제한으로 이용할 수 있는 'GPT4Free'를 개발, 레딧에 링크를 공개했습니다.
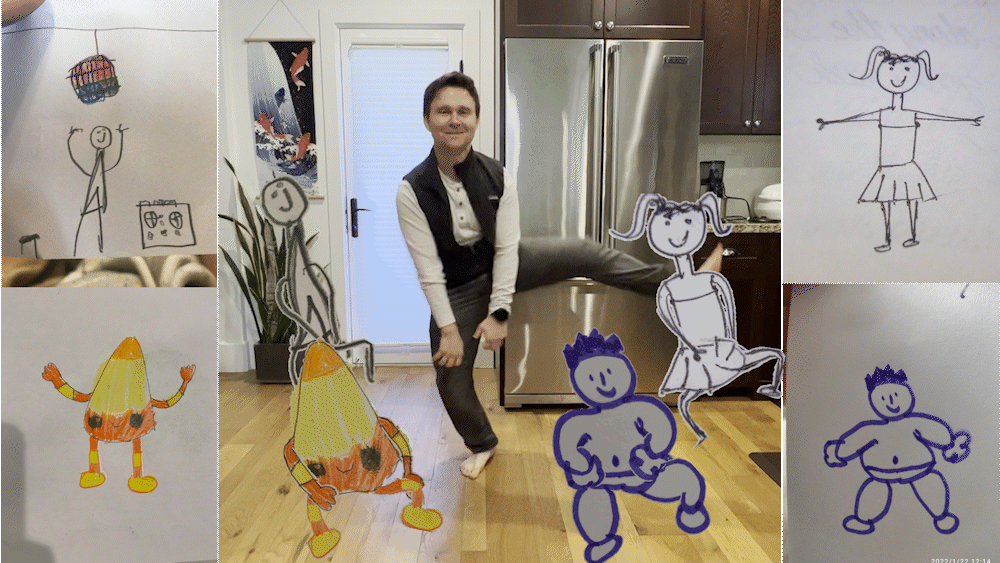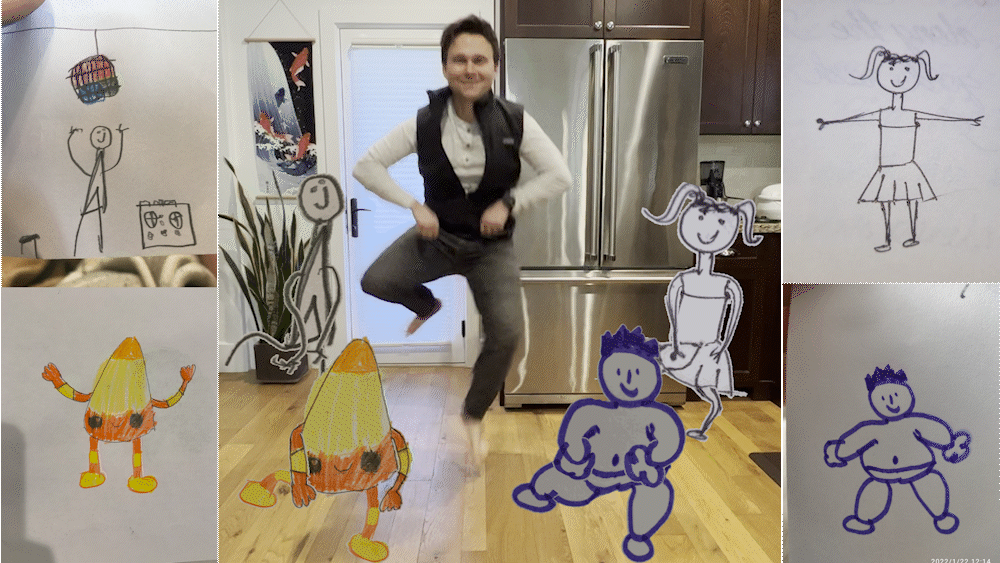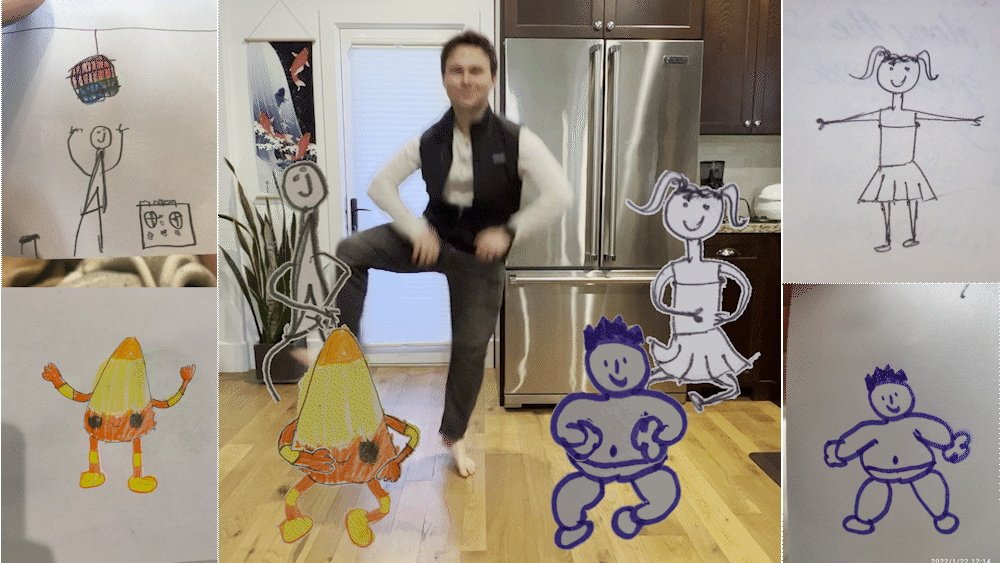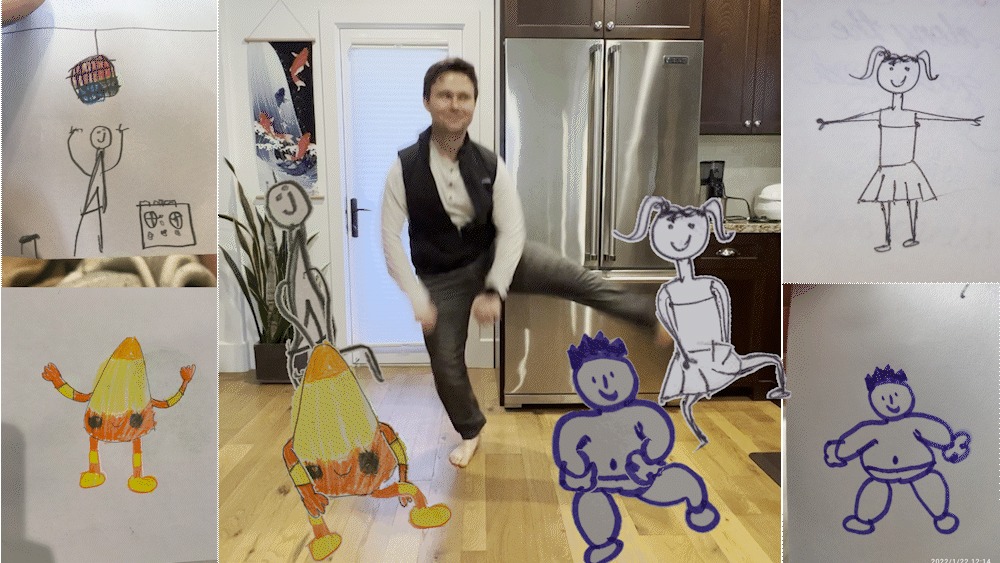
■ 메타가 손으로 그린 스케치를 애니메이션으로 만들어 주는 ‘애니메이티드 드로잉스’라는 도구를 내놨습니다. 무료 AI 도구로, 포즈를 추정해 골격 관절을 인식하는 기술 등을 이용했답니다.
■ 오픈AI가 챗GPT를 탑재한 로봇을 개발합니다. 노르웨이 로봇 기업 1X 테크놀로지에 2350만달러(약 300억원)를 투자했고, 언어모델을 장착한 휴머노이드 로봇을 개발하도록 지원할 계획입니다.
이어서 업계 소식 전해드립니다.
업계 동향

■ 엔비디아가 비디오 생성 AI 모델인 '비디오LDM(Latent Diffusion Model)'을 공개했습니다. 이 모델은 텍스트로 입력한 설명에 따라 최대 2048x1280 픽셀 해상도를 가진 동영상을 만들어낼 수 있습니다.
■ 구글이 AI 챗봇 ‘바드’에 코드 생성과 디버깅, 코드 설명 등 프로그래밍을 지원할 수 있는 기능을 탑재했습니다. 파이썬과 자바스크립트 등 20개 이상의 프로그래밍 언어를 다룰 수 있게 됐습니다.

■ 손톱 검사로 건강을 체크하거나 몸 상태에 따라 필요한 영양제를 조합해 알려주는 등의 헬스케어 제품들이 ‘월드 IT 쇼 2023(WIS 2023)’에서 인기를 끌었습니다. AI를 접목한 제품들입니다.
■ 국내 AI 스타트업들이 미국 최고 권위의 발명상인 '2023 에디슨 어워즈'에서 상을 받았습니다. CES에서도 혁신상을 받았던 누비랩과 웨인힐즈브라이언트A.I 등이 주인공입니다.
챗GPT와 대화하는 자바 앱 만들기

챗GPT 시작하기
새 자바 프로젝트 만들기
이제 새 자바 애플리케이션 만들어 보자. 여기서는 명령줄에서 메이븐(Maven)을 사용한다. <예시 1>의 코드를 사용해 새 프로젝트를 생성한다.<예시 1> 새 프로젝트 생성
/java-gpt 디렉터리에 새 프로젝트의 구조가 만들어진다. 다음 단계로 진행하기 전에 /java-gpt/pom.xml 파일로 이동해 자바 컴파일러와 소스 버전을 11로 설정한다. 이제 <예시 2> 명령을 사용해 테스트할 수 있다. 명령 결과 현재 콘솔에 “Hello, World!”를 출력한다. 이제부터는 이 명령을 사용해 애플리케이션을 실행한다.
<예시 2> 새 애플리케이션 테스트 실행하기
챗GPT 애플리케이션 설정하기
여기서 만드는 챗GPT 애플리케이션은 데모이므로 기본적인 형태로 유지한다. 사용자에게 입력 문자열을 받은 다음 AI의 응답을 콘솔에 출력한다. 우선 입력을 받는 간단한 App.java 주 클래스를 만든다. URL과 API 키를 정의하면 주 클래스가 이를 ChatBot 클래스에 전달해 실제 작업이 실행된다. <예시 3>에서 App.java 주 클래스를 볼 수 있다.<예시 3> App.java 주 클래스
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import org.json.JSONException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class App {
private static final Logger LOGGER = LoggerFactory.getLogger(App.class);
public static void main(String[] args) {
// Set ChatGPT endpoint and API key
String endpoint = "https://api.openai.com/v1/chat/completions";
String apiKey = "<YOUR-API-KEY>";
// Prompt user for input string
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
System.out.print("Enter your message: ");
String input = reader.readLine();
// Send input to ChatGPT API and display response
String response = ChatBot.sendQuery(input, endpoint, apiKey);
LOGGER.info("Response: {}", response);
} catch (IOException e) {
LOGGER.error("Error reading input: {}", e.getMessage());
} catch (JSONException e) {
LOGGER.error("Error parsing API response: {}", e.getMessage());
} catch (Exception e) {
LOGGER.error("Unexpected error: {}", e.getMessage());
}
}
}
이 클래스는 간단하다. reader.readLine()으로 사용자의 라인을 읽은 다음 이를 사용해 ChatBot.sendQuery() 정적 메서드를 호출한다. ChatBot은 잠시 후에 살펴보기로 하고, 일단 토큰을 오픈AI 챗GPT 토큰으로 설정한다. 또한 오픈AI가 오픈AI API를 계속 변경하고 있으므로 엔드포인트 URL https://api.openai.com/v1/chat/completions는 지금은 정확하지만 과거(최근도 포함)의 문서와 다를 수 있다는 점을 유의해야 한다. 오류가 발생한다면 오픈AI API의 엔드포인트 URL이 최신 상태인지 확인하면 된다.
ChatBot 클래스
또한 무슨 일이 일어나는지를 살펴보고 오류를 추적하기 위해 간단한 로거를 구성했다. 이 클래스를 지원하려면 메이븐에 몇 가지 종속 항목을 추가해야 하지만, 우선 <예시 4>의 ChatBot 클래스부터 살펴보자. 편의를 위해 둘 다 같은 패키지 범위에 넣는다.<예시 4> 간단한 ChatBot
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.ContentType;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.google.gson.Gson;
public class ChatBot {
private static final Logger LOGGER = LoggerFactory.getLogger(ChatBot.class);
public static String sendQuery(String input, String endpoint, String apiKey) {
// Build input and API key params
JSONObject payload = new JSONObject();
JSONObject message = new JSONObject();
JSONArray messageList = new JSONArray();
message.put("role", "user");
message.put("content", input);
messageList.put(message);
payload.put("model", "gpt-3.5-turbo"); // model is important
payload.put("messages", messageList);
payload.put("temperature", 0.7);
StringEntity inputEntity = new StringEntity(payload.toString(), ContentType.APPLICATION_JSON);
// Build POST request
HttpPost post = new HttpPost(endpoint);
post.setEntity(inputEntity);
post.setHeader("Authorization", "Bearer " + apiKey);
post.setHeader("Content-Type", "application/json");
// Send POST request and parse response
try (CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = httpClient.execute(post)) {
HttpEntity resEntity = response.getEntity();
String resJsonString = new String(resEntity.getContent().readAllBytes(), StandardCharsets.UTF_8);
JSONObject resJson = new JSONObject(resJsonString);
if (resJson.has("error")) {
String errorMsg = resJson.getString("error");
LOGGER.error("Chatbot API error: {}", errorMsg);
return "Error: " + errorMsg;
}
// Parse JSON response
JSONArray responseArray = resJson.getJSONArray("choices");
List<String> responseList = new ArrayList<>();
for (int i = 0; i < responseArray.length(); i++) {
JSONObject responseObj = responseArray.getJSONObject(i);
String responseString = responseObj.getJSONObject("message").getString("content");
responseList.add(responseString);
}
// Convert response list to JSON and return it
Gson gson = new Gson();
String jsonResponse = gson.toJson(responseList);
return jsonResponse;
} catch (IOException | JSONException e) {
LOGGER.error("Error sending request: {}", e.getMessage());
return "Error: " + e.getMessage();
}
}
}
ChatBot은 얼핏 복잡해 보이지만 사실은 간단하다. 가장 중요한 것은 JSON 처리다. 먼저 sendQuery()로 전달된 문자열 입력을 챗GPT가 인식하는 JSON 형식으로 마샬링해야 한다(이 부분도 최근 변화가 있었음). 챗GPT는 지속적인 대화를 허용하므로 사용자 또는 비서 역할이 태그된 메시지 모음을 찾아 이를 대화에서 오가는 응답으로 본다. 전체 대화의 “어조”를 설정하는 데 사용되는 기능도 있지만 이 속성은 일관성 없이 적용된다. 챗GPT가 기대하는 JSON 형식은 <예시 5>와 같다(오픈AI 문서에서 발췌).
<예시 5> 샘플 챗GPT 제출 형식 JSON
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
JSON 응답 설정
여기서는 하나의 role:user와 입력 문자열로 설정된 콘텐츠가 있는 간단한 메시지 모음을 사용한다. 또한 model과 temperature 필드도 설정했다. model 필드는 사용되는 챗GPT 버전을 정의하는 데 중요하며 새로운(유료) GPT-4를 포함한 여러 옵션이 있다. temperature는 AI의 “창의성(단어 재사용 방지 측면에서)”을 설정하는 GPT 기능이다.적절한 JSON을 확보하면 아파치 HTTP 라이브러리를 사용해 POST 요청을 작성하고 본문을 JSON으로 설정한다(post.setEntity() 사용). 예시에서 볼 수 있듯 이 라인으로 auth 헤더에 API 키를 설정했다.
다음으로, try-with-resource 블록을 사용해 요청한다. 오류가 없다면 응답을 완료한 후 JSON 응답 구조를 탐색해 가장 최근의 message:content를 반환한다. 이제 테스트할 준비가 거의 다 됐다. 우선 <예시 6>과 같이 pom.xml에 필요한 종속 항목을 추가한다.
<예시 6> pom.xml의 메이븐 종속 항목
이제 코드를 실행하면 <예시 7>과 같이 작동하는 모습을 볼 수 있다.
<예시 7> 자바 명령줄 애플리케이션으로 챗GPT에 말하기
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.6</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
</dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
전체 애플리케이션 코드는 필자의 java-chatgpt GitHub 리포지토리에서 볼 수 있다.
결론
여기서 살펴본 것처럼 자바로 챗GPT 클라이언트를 구축하는 방법은 매우 간단하다. JSON 처리가 약간 번거롭지만 그 외에는 여기서 소개한 데모 코드를 쉽게 확장할 수 있다. 첫 연습으로 이 챗GPT 프로그램을 지속적인 대화가 가능한 REPL(Read-Eval-Print-Loop)로 확장해 보는 것도 좋다.
태그
AI가 소설 쓰고 연애 상담해준다는데…‘챗GPT’ 능력은 어디까지, 챗GPT에 쏟아지는 폭발적 반응, 두 달 만에 1500만 유저…구글 ‘비상’, 챗GPT, 어디까지 할 수 있을까, 챗GPT와 대화하는 자바 앱 만들기, 챗GPT, 쉿! 채팅내용 비공개 기능, 새 자바 프로젝트 만들기, 자바 명령줄 애플리케이션으로 챗GPT에 말하기, ChatBot 클래스
'AI-Prompt Engineering' 카테고리의 다른 글
| AI 기술 발전과 그 미래 전망 (4) | 2024.12.17 |
|---|---|
| 도커와 쿠버네티스로 혁신적 배포 관리 (1) | 2024.12.09 |
| 거대 AI 최신 키워드 : #소비자 #효율 (0) | 2023.06.23 |
| 사람과 대화하는 인공지능 ChatGPT, 의료 분야에서는 어떻게 활용될까? [ChatGPT 대안 중 최고의 AI 챗봇은?] (1) | 2023.06.22 |
| AI가 배출한 新직업 ‘프롬프트 엔지니어’ 뭐길래 [“초봉 4억원”… 억대 연봉자들의 일, 돈, 삶] (2) | 2023.06.09 |
| 캐즘 마케팅, 시장에서 오래 살아남기 위한 전략적 마케팅 [전략과 문제해결·캐즘(Chasm), 실습사례(case study) HRDInsight] (0) | 2023.06.04 |
| 챗gpt ChatGPT를 이용한 블로그 키워드 추출 방법 [챗GPT 일 잘 시키는 실전 팁] (1) | 2023.06.04 |
| Google Apps Script로 네이버 뉴스를 채팅방으로 전송하는 서버리스 뉴스봇 만들기 (0) | 2023.06.01 |



